
K近邻算法:机器学习萌新必学算法
日期: 2020-10-30 分类: 跨站数据 502次阅读
摘要:K近邻(k-NearestNeighbor,K-NN)算法是一个有监督的机器学习算法,也被称为K-NN算法,由Cover和Hart于1968年提出,可以用于解决分类问题和回归问题。
1. 为什么要学习k-近邻算法
k-近邻算法,也叫KNN算法,是一个非常适合入门的算法
拥有如下特性:
● 思想极度简单
● 应用数学知识少(近乎为零)
● 对于各位开发者来说,很多不擅长数学,而KNN算法几乎用不到数学专业知识
● 效果好
○ 虽然算法简单,但效果出奇的好
○ 缺点也是存在的,后面会进行讲解
● 可以解释机器学习算法使用过程中的很多细节问题
○我们会利用KNN算法打通机器学习算法使用过程,研究机器学习算法使用过程中的细节问题
● 更完整的刻画机器学习应用的流程
○ 对比经典算法的不同之处
○ 利用pandas、numpy学习KNN算法
2. 什么是K-近邻算法

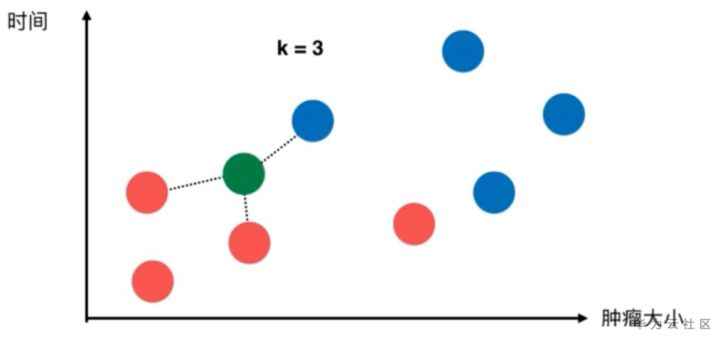
上图中的数据点是分布在一个特征空间中的,通常我们使用一个二维的空间演示
横轴表示肿瘤大小,纵轴表示发现时间。
恶性肿瘤用蓝色表示,良性肿瘤用红色表示。
此时新来了一个病人

如上图绿色的点,我们怎么判断新来的病人(即绿色点)是良性肿瘤还是恶性肿瘤呢?
k-近邻算法的做法如下:
取一个值k=3(此处的k值后面介绍,现在大家可以理解为机器学习的使用者根据经验取得了一个经验的最优值)。
k近邻判断绿色点的依据就是在所有的点中找到距离绿色点最近的三个点,然后让最近的点所属的类别进行投票,我们发现,最近的三个点都是蓝色的,所以该病人对应的应该也是蓝色,即恶性肿瘤。
本质:两个样本足够相似,那么他们两个就具有更高概率属于同一个类别。
但如果只看一个,可能不准确,所以就需要看K个样本,如果K个样本中大多数属于同一个类别,则被预测的样本就很可能属于对应的类别。这里的相似性就依靠举例来衡量。
这里我再举一个例子
● 上图中和绿色的点距离最近的点包含两个红色和一个蓝色,此处红色点和蓝色点的数量比为2:1,则绿色点为红色的概率最大,最后判断结果为良性肿瘤。
● 通过上述发现,K近邻算法善于解决监督学习中的分类问题
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐