
最佳实践 | SequoiaDB单中心三副本部署规划
日期: 2020-12-04 分类: 跨站数据 579次阅读
01 概述
随着互联网业务蓬勃发展,大规模高并发交易处理、海量数据处理与分析需求不断增长的背景下,国产金融级分布式数据库SequoiaDB巨杉数据库的统一存储和管理海量结构化、非结构化数据的能力得到了广大用户的认可。
SequoiaDB巨杉数据库自研的原生分布式存储引擎支持完整ACID,具备弹性扩展、高并发和高可用特性,基于同一的原生分布式数据库底座,提供基于内核级的DBaaS云原生数据库能力。提供高达8种SQL、NoSQL及对象存储实例,包括:
提供原生的SDB API进行数据库管理及数据CURD操作;
提供兼容 MySQL、MariaDB、PostgreSQL 与 SparkSQL的四种关系型数据库实例;
提供兼容基于JSON的JSON文档类MongoDB数据库实例;
提供兼容S3对象存储与PosixFS文件系统的非结构化数据实例。
作为一个拥有全分布式系统架构的数据库,SequoiaDB 支持各种灵活的部署方式。本文主要将以三副本为例,介绍SequoiaDB巨杉数据库在单数据中心下部署规划最佳实践。
02 部署规划最佳实践探索
2.1 软硬件环境配置
SequoiaDB 作为一款高性能分布式关系型数据库,支持 Linux 操作系统环境,支持绝大多数的主流硬件网络,并能够部署和运行在 x86及 ARM 架构服务器环境和主流虚拟化环境。本文所展示的三副本部署规划实践中的服务器配置,如下表所示。

(关于更多SequoiaDB的硬件要求可参考文档:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1561381803-edition_id-500#受支持的硬件平台)
本次示例的软件配置如下。
操作系统:CentOS 7.6
SequoiaDB版本:5.0.1
(关于更多SequoiaDB的硬件要求可参考文档:http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1561381803-edition_id-500#受支持的操作系统)
2.2 物理架构部署规划
本文以三台物理机服务器的部署规划最佳实践进行探索,首先我们需要对物理机的磁盘进行测试和规划,规划时往往需要从以下几个方面进行考虑:
对于磁盘的配置是选择用裸盘还是用RAID,各有什么优缺点
决定了磁盘的配置后如何规划数据组的数量?
数据分布怎么配置更合理?
接下来我们将对上述问题进行探索实践。
![]() 问题一:裸盘还是RAID
问题一:裸盘还是RAID
对于磁盘的规划使用,我们分别进行了两组实验来对比裸盘和RAID的性能。
实验场景(每个数据组三副本):
1. 磁盘在raid5模式下,LOB数据的写入性能测试。
2. 磁盘在直通模式下,LOB数据的写入性能测试。
实验方法:
模拟场景,向数据库写入800w张100KB的图片,写入完成之后再触发全量同步观察写入磁盘写入速度。
实验结果:

从以上测试结果可以看出,使用6块裸盘的写入性能高于RAID5模式。巨杉数据库本身以三副本模式进行部署,保证了数据库的高可用性,因此在一般场景下我们推荐使用裸盘进行部署巨杉数据库。
那么使用裸盘是否存在什么弊端,什么场景下推荐使用RAID5 呢?在使用裸盘的过程中,很多用户慢慢发现磁盘一旦损坏在更换磁盘的时候需要人工介入进行节点启停、磁盘挂载等一系列操作,而使用RAID5划分磁盘就可以完美的避免这些操作,因此当应用对于读写性没有很高时候,使用RAID5可以在满足性能要求的同时减少故障发生时的人工介入工作。
![]() 问题二:数据节点数量规划
问题二:数据节点数量规划
为避免多个数据节点部署在一块盘上,在业务压力大时候发生IO抢占的问题,我们建议按照每块盘上部署一个数据节点的方式来规划,最终数据节点规划方案如下图。

![]() 问题三:如何规划数据分布
问题三:如何规划数据分布
SequoiaDB在集群的管理上定义了数据域、分区组的概念。数据域由若干个复制组(ReplicaGroup)组成的逻辑对象。每个域都可以根据定义好的策略自动管理所属数据,如数据切片和数据隔离等。分区组又被称为复制组,一个复制组内可以包含一个或多个数据节点(或编目节点),节点之间的数据使用异步日志复制机制,保持最终一致。
一个集群可以根据不同的业务系统来划分不同的数据域,不仅实现将不同业务系统数据在物理层面的隔离存储,同时也实现了不同业务系统数据的统一调度管理,而且以后的集群扩容也可以根据域的使用需求而只针对此域进行集群扩容,假定将测试环境的数据域按照存储数据的结构来划,则数据域规划方案如下:

而在一个域内部,则可以根据业务数据的特性采用灵活的分区管理方式,将一张表的存储分散到多个物理位置,大大的减少单次操作读取的数据量,例如对于超大表,多采用多维分区的方式将业务数据集合分成多个子集合,每个子集合的数据分布在数据域内所有的复制组中,对于一些存储配置信息的小表则可以存储在指定复制组中,数据存储示意图如下:

下面演示一下如何划分数据域,以及如何通过不同的分区方式来管理超大表和小表。具体步骤如下。
1. 划分数据域
创建结构化域d1

创建非结构化域d2

2. 利用多维分区表管理超大表
创建表空间metaCS
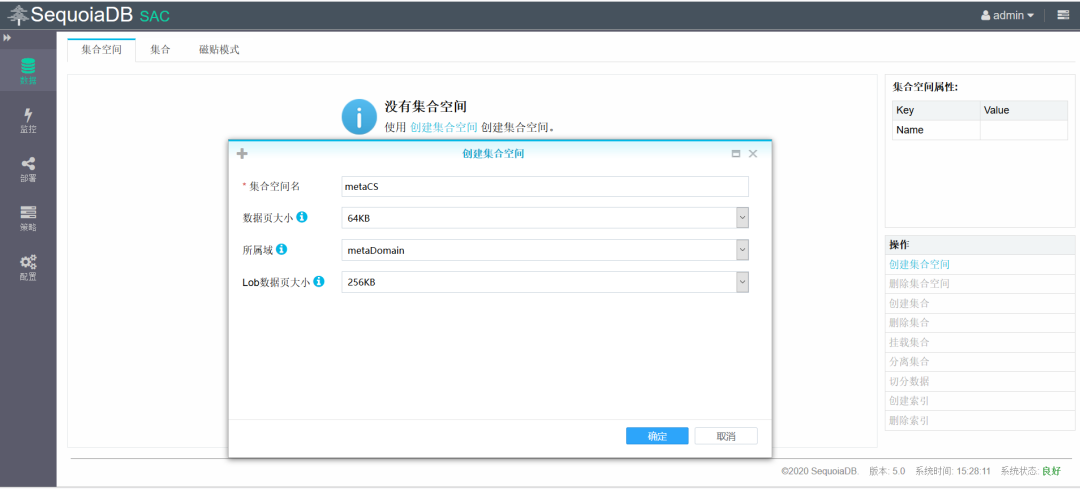
创建主表’metaCL’

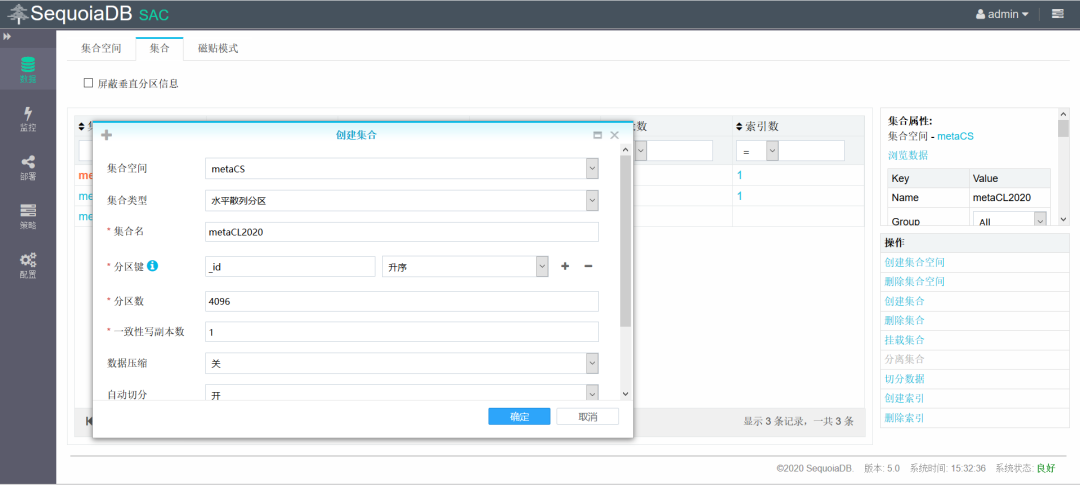
创建子表metaCL2020用于存储2020年的数据
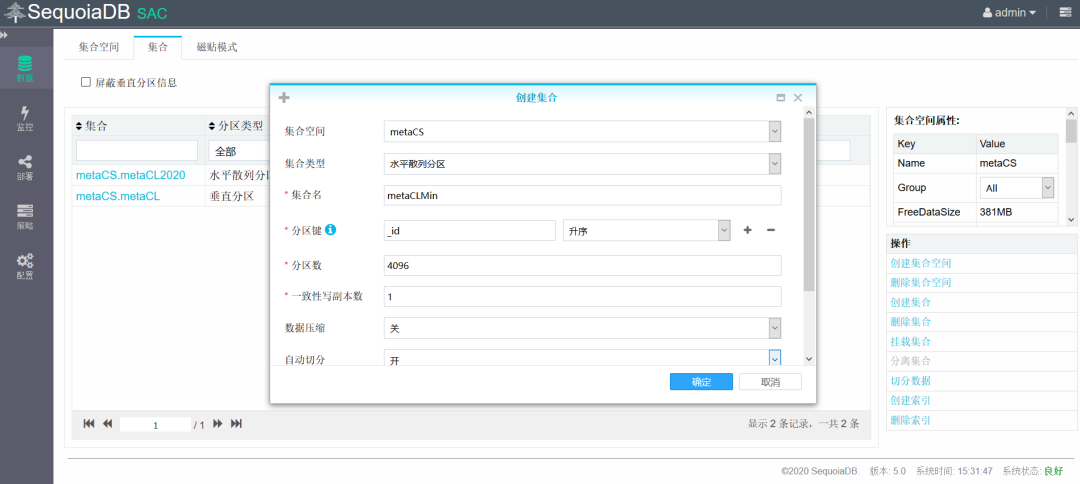
创建子表metaCLMin用于存储2020年以前的数据
创建子表metaCLMax用于存储2020年之后的数据

将子表metaCL2020挂载到主集合上,用于存储2020年的数据
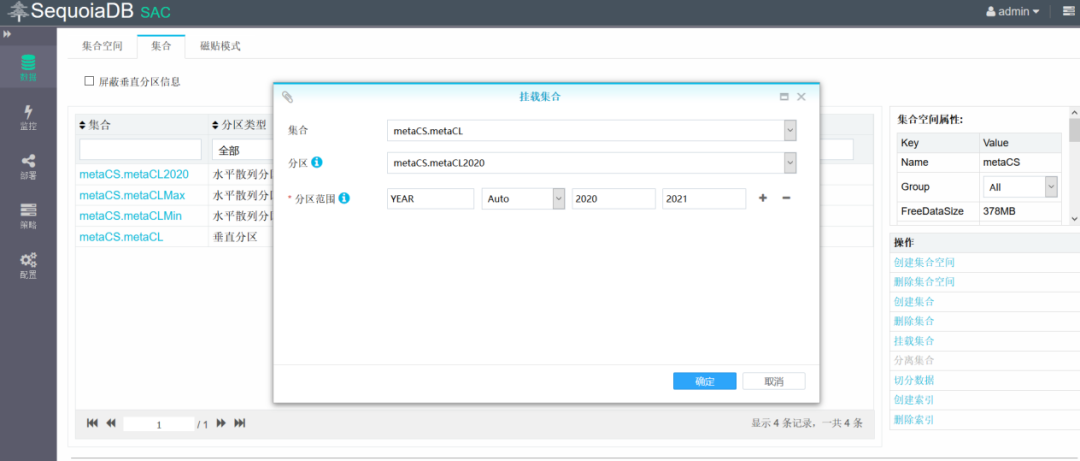
将子表metaCLMin挂载到主集合上,用于存储2020年以前的数据

将子表metaCLMax挂载到主集合上,用于存储2020年以后的数据

创建完多维分区表之后,我们简单插入几条数据:
{"YEAR": 2021, "Name": "Meppo"}
{"YEAR": 2020, "Name": "Tiny"}
{"YEAR": 2019, "Name": "Tommy"}
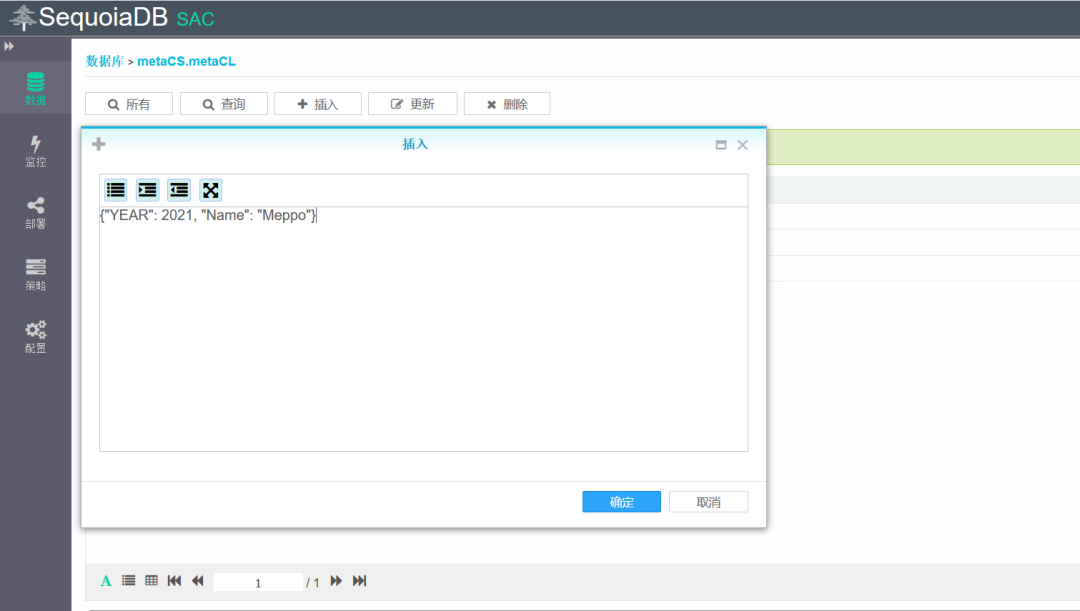
查看数据分布,可以看到数据根据YEAR的分区规则进入了各自的子表中
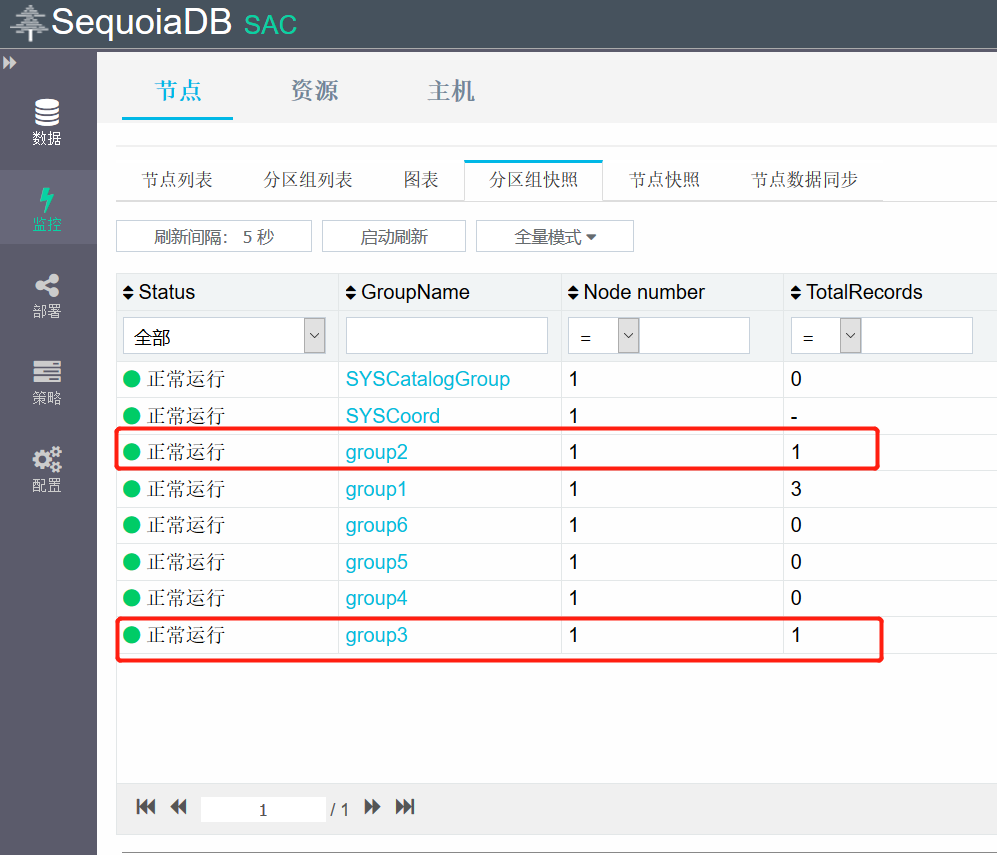
下面我们再向集合中插入几条数据,验证数据是否会分布在不同复制组中,可以看到新插入的数据都分布到了group2和group3中
{"YEAR": 2020, "Name": "Lion"}
{"YEAR": 2020, "Name": "Luna"}
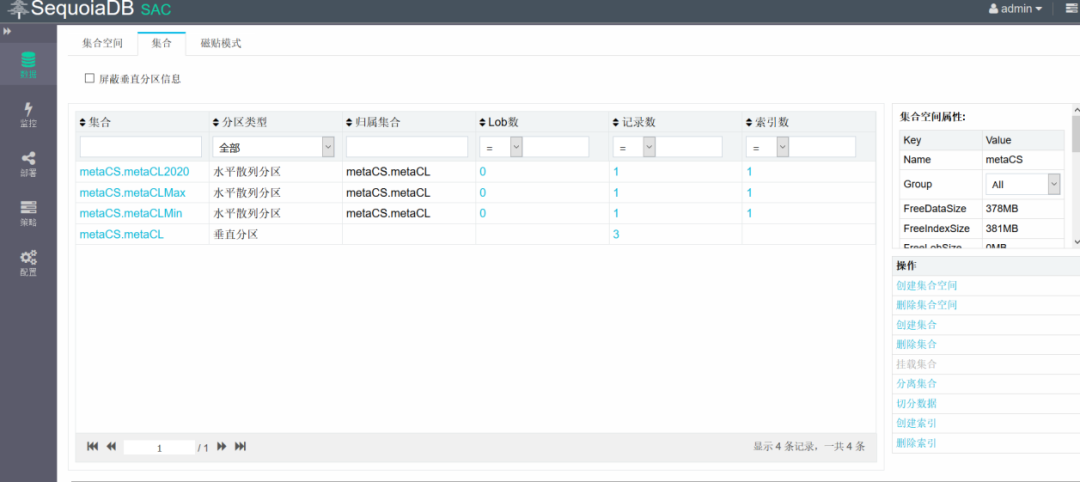
3.将小表的数据存储在指定复制组中
新建smallCL表,分区组指定为group1
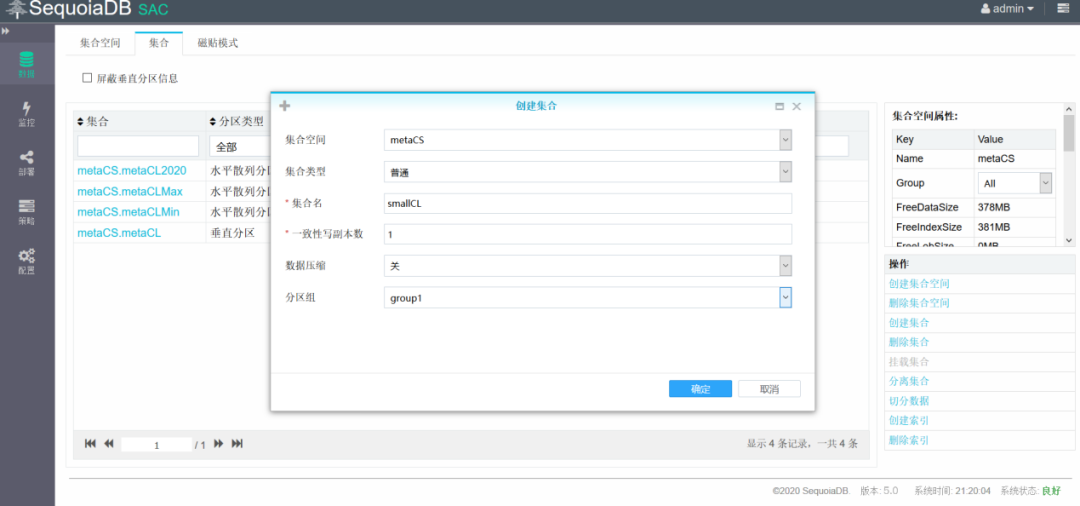
向集合中插入三条测试数据
{"name":"Tiny"}
{"name":"Lion"}
{"name":"Meepo"}
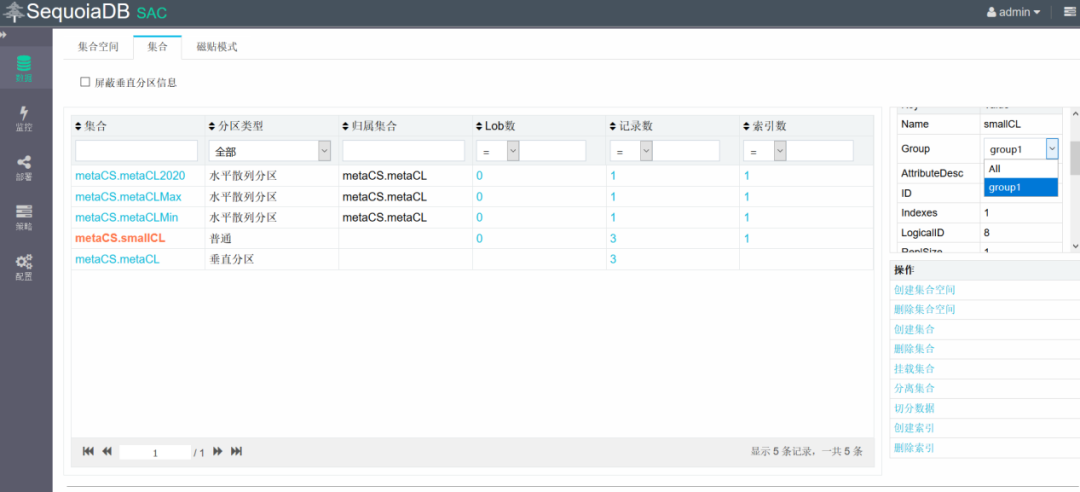
查看smallCL表的数据分布,所有数据全都存在指定的数据组group1上,可以看到所有的数据都存储在group1中
03 总结
没有”完美”的规划,只有合适的规划,SequoiaDB作为一款开源的金融级分布式关系型数据库,系统部署规划方案灵活可配,用户可以通过数据域的划分让用户可以在复杂集群环境中对资源进行逻辑与物理划分隔离,可以划分多个数据组来解决单点数据量大的问题,可以选择裸盘使用来追求最佳性能,也可以使用硬盘做RAID来降低日常运维的难度,因此只要确认好实际的业务需求,就能制定合适的部署规划方案。
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐