
巨杉分布式数据库在民生银行的使用
日期: 2020-11-30 分类: 跨站数据 647次阅读
数据库是银行金融行业不可或缺的「数据基础设施」,随着银行业务的快速发展,特别是在金融科技的持续创新驱动下,针对多类型数据进行综合处理。本期案例分享特别邀请到来自民生银行信息科技部的史国畅,给大家分享民生银行应用巨杉分布式数据库的相关实践。
本次分享主要分为四个部分:第一部分介绍平台的实现背景,第二部分是平台实现的细节,第三部分是平台的部署情况,最后介绍民生银行平台中使用巨杉数据库的最佳实践。
巨杉数据库SequoiaDB作为一款金融级分布式数据库,具备弹性扩展、高并发和高可用等特性,支持块存储,同时巨杉的多模特性能够为不同的应用提供多种灵活的访问接口,目前支持MySQL、PGSQL、MongoDB、MariaDB、Spark、S3、PosixFS多种引擎。技术实现上,巨杉数据库SequoiaDB能够通过主子表方式实现水平或垂直的分区。

巨杉分布式数据库在民生银行的使用场景主要包括以下三种:一是海量数据查询平台;二是归档数据存储平台;三是非结构化数据管理平台。承载这三大业务场景的是民生银行的大数据平台非计算集群,其定位是海量数据存储和低延时高并发联机查询。在大数据平台非计算集群当中,存储层支持结构化、半结构化数据和非结构化数据。接口层方面,支持API和标准SQL连接。在此基础上,我们还提供了web service的同步和异步的接口,接入民生银行内部的运维视点查询平台等,对外提供服务。
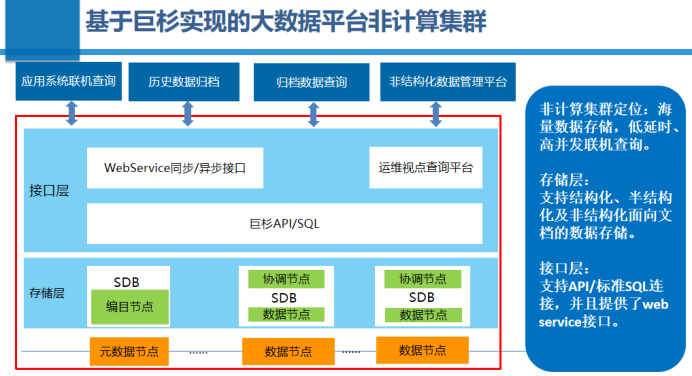
目前,大数据非计算管理平台在民生银行内的部署情况如下:
-
主备两个机房,三套集群,对重要系统进行灾。其中,主机房共部署112台主机,其中管理主机9台,数据主机103台。备机房共部署54台主机,其中管理主机6台,数据主机48台。
-
从数据量来看,主机房裸数据量大约820TB,三副本数据量共2460TB。关系型数据存储裸量约220TB,数据记录数共2000亿左右。
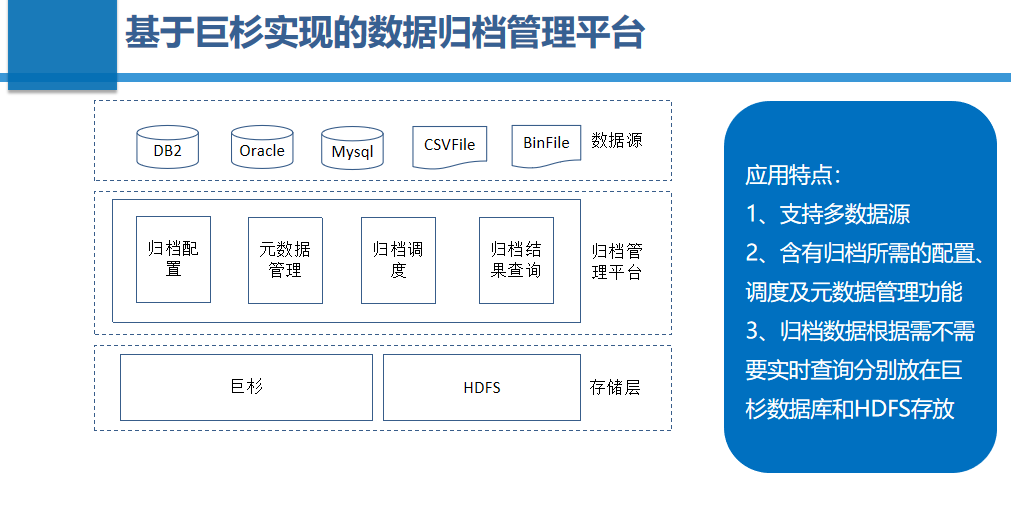
基于巨杉实现的归档数据存储平台
海量数据查询平台的数据来源是在线的各种业务系统,包括联机交易系统、批处理系统、内部管控系统以及Oracle、DB2和 MySQL等数据库,甚至一些文件,都会根据线上要求,存放最少的数据量。其余数据会根据是否需要实时查询,分别放在巨杉数据库和HDFS存放。当中巨杉数据库用于汇总需要进行历史数据实时查询的业务。民生银行基于此架构,实现了归档管理平台的归档配置、元数据管理、归档调度以及归档结果查询等一系列完备的数据归档流程数据管理。
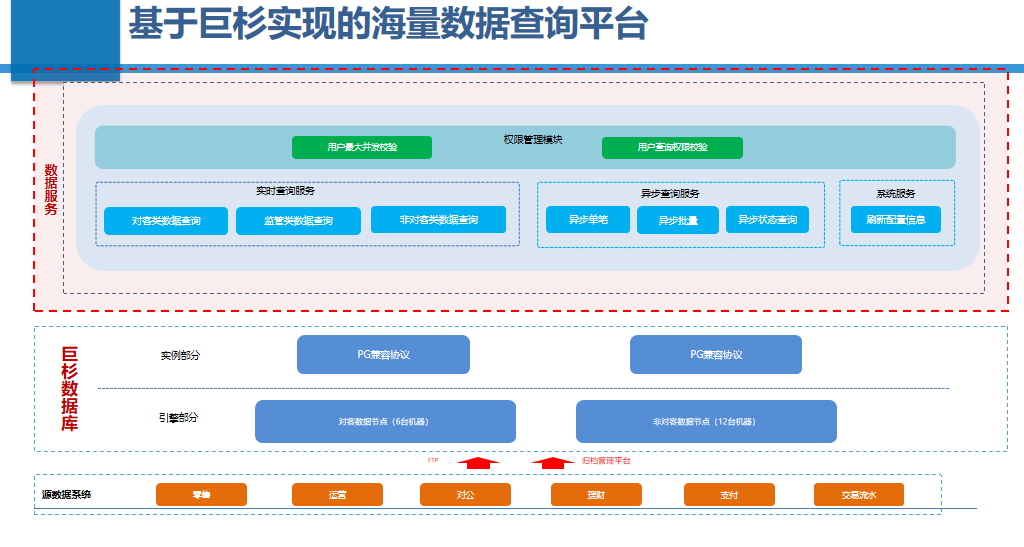
基于巨杉实现的海量数据查询平台
对于归档的数据,海量数据查询平台提供对外查询的接口。该平台底层采用巨杉分布式数据库,通过PostgreSQL兼容的关系型SQL协议,对外提供查询服务。从实时查询来说,分为对客类数据查询、监管类数据查询以及非对客类数据查询。其中,对客类的数据查询支持在线业务,比如在线系统一年前的数据已经归档到大数据非计算管理平台中,我们就会使用海量数据查询平台的对客类对外提供服务。同时,为了满足监管需求,我们会对数据进行加工,并存储在该平台供监管查询使用。非对客类数据查询则提供对内的查询服务。另外,除了实时查询服务外,我们也提供异步查询服务,包括异步单笔、异步批量和异步状态查询等一系列场景服务。在该平台上层,我们也提供用户最大并发校验和用户查询权限校验等安全限制。
基于巨杉实现的非结构化数据管理平台
该平台主要存放民生银行的各种非结构化数据,比如图片、扫描件、人脸识别的图像、录音录像等。目前,非结构化管理平台的影像总容量为600TB。日增容量300GB;上传量达到120万笔/日 ;上传峰值>2000笔/分钟 ;下载峰值近2500笔/分钟;已接入的各类系统达到100套。
下图展示了民生银行非结构化管理平台中,已上线系统中的记录数和数据容量:

由于民生银行的非结构化的数据量较大,如果都采用高配的主机硬件,成本会大幅提高,因此我行与巨杉数据库一起对非结构化数据管理平台的架构进行了优化。该平台采用了温热数据生命周期管理。当前的数据存放到高配的SSD主机中,而一定时间以前的数据通过温热同步程序同步到大容量的主机中,能够显著地降低成本。

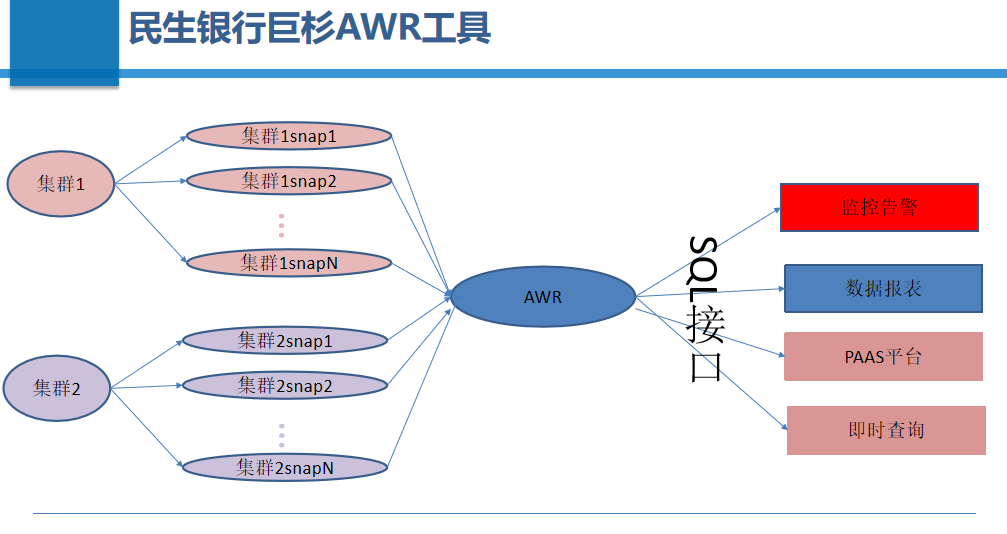
NoSQL高性能写入+SQL通用语法,检索AWR性能监控数据
由于巨杉数据库的元数据信息大多是通过NoSQL接口提供,NoSQL接口在单表查询时效果较好,而在涉及复杂查询时成本较高。同时,在多表关联查询时的成本更高。这都是我们遇到的一些问题。经过与巨杉数据库一段时间的磨合和演进后,我们共同开发了AWR工具。该工具通过分布式采集系统将数据集中到AWR的集中存储里,该集中存储也充分利用了巨杉的多模特性,将数据以NoSQL方式存放到巨杉数据库中。但是通过SQL接口对外提供访问,并且存放了历史数据信息。通过AWR工具的SQL接口,我们可以对外提供监控告警、数据报表、PAAS平台和即时查询,可以全面实时掌握巨杉数据库的整体运行和健康情况。
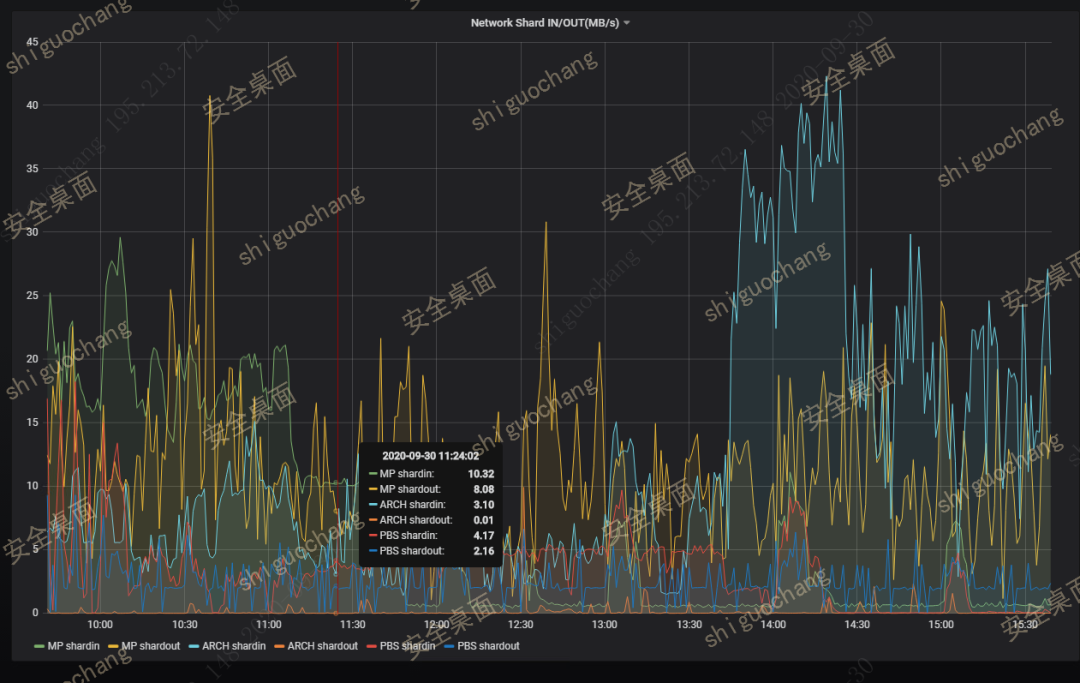
最后是PAAS平台的展现,比如通过AWR元数据信息和开源的Grafna,将巨杉数据库整体的运行状况、网络流量、QPS和TPS等,利用可视化方式展现出来。由于民生银行的数据量较大,单集群数据节点可达到1000个,通过可视化的方式能够更快的定位和解决问题。
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐