
【数据结构与算法】详解什么是树结构,并用代码手动实现一个二叉查找树
日期: 2020-09-02 分类: 跨站数据 637次阅读
本系列文章【数据结构与算法】所有完整代码已上传 github,想要完整代码的小伙伴可以直接去那获取,可以的话欢迎点个Star哦~下面放上跳转链接
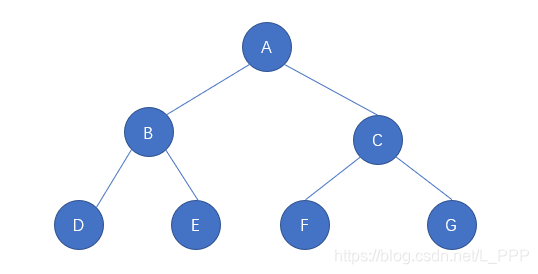
本篇文章将开始讲解树结构。其实树结构是平日里我们常见的一种数据结构,例如家族族谱、公司管理层级结构图等,这样的数据结构的存在一定有一定的道理。
- 家族族谱图
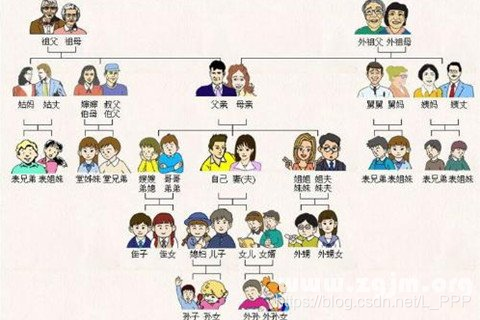
- 公司管理层级结构图
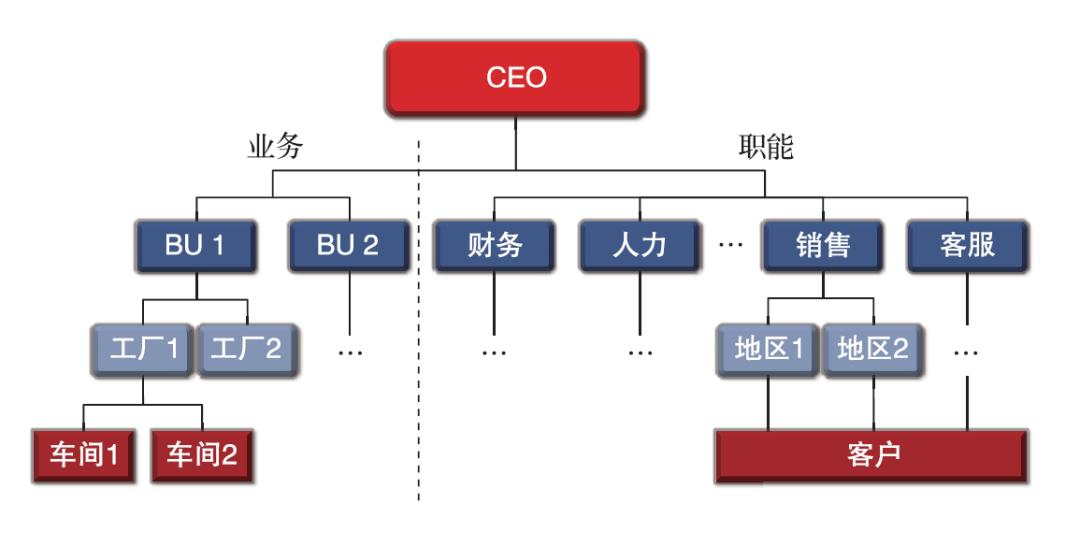
因此,在计算机领域中,树结构也是会被广泛用到的,例如数据库系统中就有用到。那么本文就从零开始学习一下树结构,并且也会封装一个二叉查找树,本文 3万+ 的详细教程,希望大家耐心观看,我是以一个纯小白的角度来写的这篇文章,相信大家认真看一定都能看懂的
- 公众号:前端印象
- 不定时有送书活动,记得关注~
- 关注后回复对应文字领取:【面试题】、【前端必看电子书】、【数据结构与算法完整代码】、【前端技术交流群】

数据结构——树结构
一、什么是树
树在我们平日应该算是一个低头不见抬头见的东西了。这里我特地找了个比较好看的树放在这里,大家可以观察一下树的特点,如图

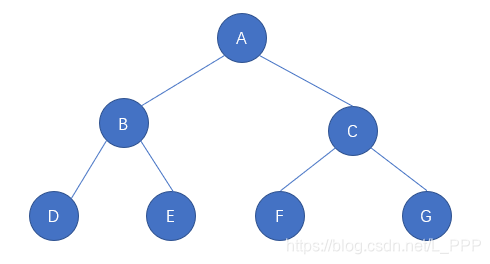
第一反应是不是从树根开始往上生长,分出了特别的多分叉?没错,咱们要学习的树结构就是参照着真正的树衍生过来的,只不过是一个倒着的抽象的树,如图
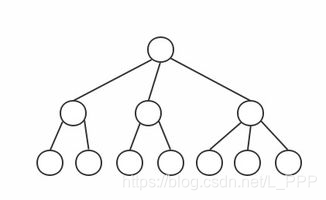
我们把图中第一层的圆圈看成是树根,以下的几层都是由树根延伸出去的分支,这里的每一个圆圈都可以用于存储我们的数据。
树是一种非线性数据结构,它是由一个或多个结点组成的
二、树结构的优点
总的来说,树结构是结合了之前我们讲过的数组、链表、哈希表等结构的优缺点,但也不能说哈希表是最好的数据结构,毕竟每种数据结构都有各自突出的优点
树结构的优点:
- 空间利用率比较高
- 可以非常快速地查找到最大值和最小值
三、树结构的术语
因为本文是从零开始学习树结构,所以我们在这里有必要讲解一下,在我们封装各种树结构的过程中涉及到的术语,方便大家理解。
| 术语名 | 含义 |
|---|---|
| 结点 | 树中的数据元素 |
| 结点的度 | 结点拥有的子树个数 |
| 叶子结点 | 度为0的结点 |
| 分支结点 | 度大于0的结点 |
| 父节点 | 衍生出其它结点的结点为这些结点的父结点 |
| 子结点 | 被某个结点衍生出来的结点为该结点的子结点 |
| 兄弟结点 | 具有同一个父节点的所有结点为兄弟结点 |
| 结点的层次 | 设定根结点所在层次为1,其它结点层次为其父节点层次+1 |
| 树的深度 | 树的所有结点中的最大层次为该树的深度 |
| 路径 | 从某个结点沿着树的层级关系到达另一个结点之间的路线 |
| 路径长度 | 路径上的结点个数 -1 |
我们来用图讲解一下每个术语的含义

如图,每一个圆圈就是一个结点,结点A 延伸出去三个结点,因此 结点A 的度为 3 ;结点B 延伸出去两个结点,因此 结点B 的度为 2 ;结点C 并没有延伸出去的结点,故 结点C 的度为 0
图中像 结点C 一样的度为 0 的结点还有 结点D 、结点E 、结点F,它们都称为叶子结点 ; 那么相对的,结点A 、结点B 的度都不为 0,它们就称为分支结点
对于 父结点 、子结点 、兄弟结点,我们把图中的树结构看成族谱就很好理解了,假设 结点B 是 爸妈,其延伸出去两个结点 结点E 、结点F,那么就是 B 生了 E 和 F,所以 结点B 就是 结点E 和 结点F 的父结点 ; 结点E 和 结点F 就是 结点B 的子结点 ;结点E 和 结点F 互为兄弟结点
树结构我们可以进行层次分级,例如统一规定根结点所在层次为 1,接着往下层级逐渐 +1。如图,结点A 所在的层次为 1;那么它的下一层层级就为 2,也就是 结点B 、结点C 、结点D 所在的层次为 2 ;再往下一层,结点E 、结点F 所在的层次为 3,这就是结点的层次。因为该树结构的最大层次为 3,所以该树的深度就为 3
对于路径,假设我们要找到 结点A 到 结点E 的路径,我们只需要沿着树的层次结构走就可以了,如图红线所标的路线就称为 结点A 到 结点E 的路径
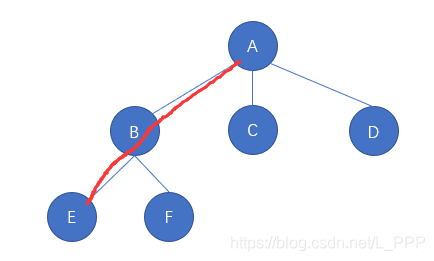
那么路径的长度为多少呢?因为该路径上经过了 3 个结点,因此,该路径的长度为 2
四、什么是二叉树
在树结构中,我们用到的最多的就是二叉树,因此它也是我们重点学习的对象,并且本文最后是要进行二叉查找树的代码封装,那么我们还是要先来了解一下二叉树的定义
二叉树的定义: 树结构中每个结点最多只有两个子结点,即任何一个结点的度都小于等于 2
我自己画了几个图来给大家举例哪些是二叉树,哪些不是
首先说明,二叉树可以为空,也就是结点个数可以等于 0,此时称之为空二叉树
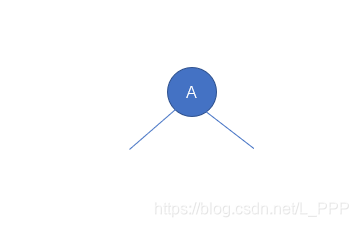
该树结构只有一个根节点,符合二叉树的定义,因此这是一个非空二叉树

该树结构不是二叉树,因为 结点A 有三个子结点,不符合二叉树的定义
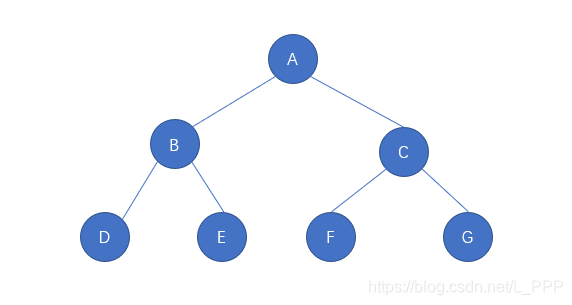
该树结构是一个非空二叉树
正是因为二叉树只有两个子结点,因此我们可以简单得把位于左侧和位于右侧的两个子结点分别称作其父节点的 左子结点 和 右子结点 。
讲到这里,我再补充个概念,叫做 左子树 和 右子树 。因为我们整个二叉树就像是一棵树嘛,那么当我们以某个结点当作根结点,我们可以把其左边的所有结点组成的结构看成是一颗小一点的树,称之为 左子树 ;同理,其右侧所有结点组成的结构称之为 右子树 。如图

其实在二叉树中,又有两种特殊的二叉树,即 完美二叉树 和 完全二叉树,接下来我们来简单讲解一下这两种类型的二叉树的概念
五、完美二叉树
完美二叉树 又叫 满二叉树,顾名思义,就是在一个二叉树中,除了最后一个层级的叶子节点外,其余每个结点都有两个子结点
如图就是一个满二叉树

再来看一个不是满二叉树的例子,如图
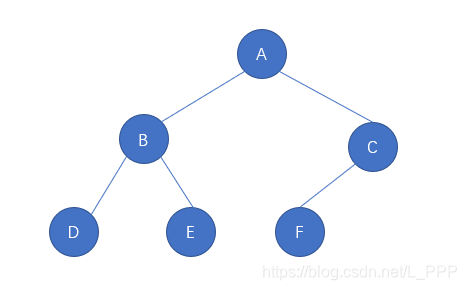
该二叉树就不是一个满二叉树,因为处于倒数第二层的 结点C 只有一个子结点,不满足满二叉树的定义
六、完全二叉树
完全二叉树要满足以下两个条件:
- 除了最后一层外,其它各层的结点个数都达到最大个数
- 最后一层的结点集中在左侧,且结点连续,只有右侧部分可以缺失结点
光看定义难以理解,我们来用实例了解完全二叉树

这不是一个完全二叉树。其满足了完全二叉树的第一个条件,第一层最大结点个数应为 1,它有 1 个结点 ;第二层最大结点个数应为 2,它有 2 个结点 ;第三层最大结点个数应为 4,它有 4 个结点。
但其不满足完全二叉树的第二个条件,因为最后一层的 结点H 、结点I 、结点J 没有连续集中在左侧。
那么如何才算是连续集中在左侧呢?只需要在此图中给 结点D 添加一个右子结点即可使最后一层的结点连续集中在左侧,如图

这就是一个正确的完全二叉树
再来看一个例子,如图
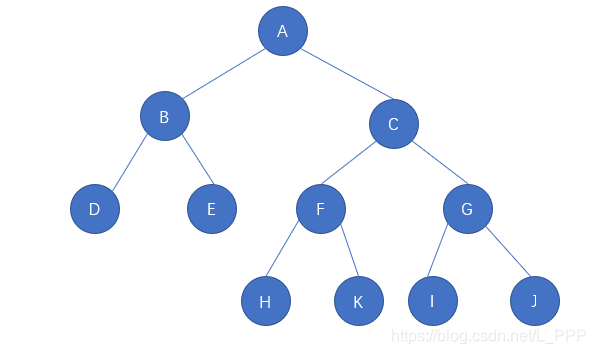
这就不是一个完全二叉树了,虽然最后一层的结点连续集中在一起,但是它们集中在最后一层的右侧,这并不满足完全二叉树的定义
其实 满二叉树 是一种特殊的 完全二叉树,不信你可以自己举个简单的例子验证一下
七、二叉树的特性
二叉树作为树结构中一种特殊的类型,它是有一些自己的特性的,我们来看一下
(1)特性一
一个二叉树第 i 层的最大结点个数为
2
i
−
1
(
i
>
=
1
)
2^{i-1}(i>=1)
2i−1(i>=1);
在二叉树中,结点个数最多的情况就是满二叉树,即除了最后一层的叶子结点外,其余结点都有两个子结点,因此满二叉树每一层的结点个数都达到了最大值,其余类型的二叉树每一层结点个数只会小于或等于它
我们可以自己来验证一下,下图时一个树的深度为 3 的满二叉树
第一层结点个数最多只有
2
0
=
1
2^0 = 1
20=1 个,图中有一个结点
第二层结点个数最多只有
2
1
=
2
2^1 = 2
21=2 个,图中有两个结点
第三层结点个数最多只有
2
2
=
4
2^2 = 4
22=4 个,图中有四个结点
(2)特性二
深度为 k 的二叉树拥有的最大结点数为
2
k
−
1
(
k
>
=
1
)
2^k-1(k>=1)
2k−1(k>=1);
同样的,满二叉树是二叉树中结点个数最多的,因此其结点个数公式就为 2 k − 1 ( k > = 1 ) 2^k-1(k>=1) 2k−1(k>=1)
我们可以验证一下

这是一个深度为 1 的满二叉树,最大结点个数为
2
0
−
1
=
1
2^0-1 = 1
20−1=1 个

这是一个深度为 2 的满二叉树,最大结点个数为
2
2
−
1
=
3
2^2-1 = 3
22−1=3 个
这是一个深度为 3 的满二叉树,最大结点个数为
2
3
−
1
=
7
2^3-1 = 7
23−1=7 个
(3)特性三
在非空二叉树中, n 0 n_0 n0 表示叶子结点个数, n 1 n_1 n1 表示分支结点个数,那么它们满足的关系有 n 0 = n 1 + 1 n_0=n_1 + 1 n0=n1+1;
该特性也是一个总结出来的规律,大家了解一下即可,可以自行验证一下
八、二叉树的存储
在使用二叉树存储数据时,我们有两种选择,一种是数组存储,另一种是链表存储
(1)数组存储
当使用数组存储时,如图

在按照从上到下,从左到右的顺序给二叉树标上下标以后,我们发现在使用数组存储二叉树的数据时,很难或者说几乎无法分辨结点之间的结点关系
因此,有一种解决办法就是将二叉树补全成一个满二叉树,然后下标仍是按照从上到下,从左到右的顺序给的,如图
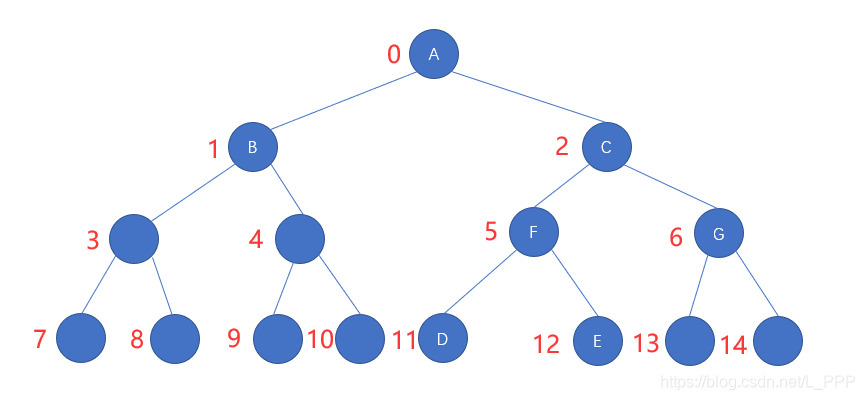
此时,我们就可以看到,各个结点之间就可以分辨得出来了,即父节点的下标值 index * 2 + 1,就等于其左子结点的下标值 ;同样的,父节点的下标值 index * 2 + 2,就等于其右子结点的下标值
虽然现在结点间的关系可以辨别得出来了,但是有没有发现,这造成了很大的空间浪费,整个数组长度为 15,空着的位置就有 8 个
所以我个人认为,用数组来存储二叉树的数据不太合适
(2)链表存储
链表存储也是二叉树最常用的一种存储方法。我们可以通过给每个结点封装一个对象,通过 left 和 right 分别指向其左子结点和右子结点
来看一下,用链表存储的二叉树的样子,如图
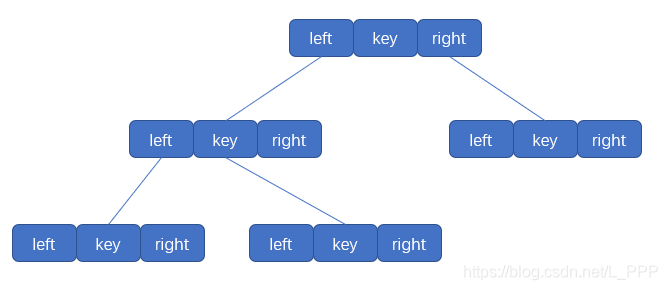
我们只需要调用某结点的 left 或 right 就可以找到其子结点,这样做既避免了空间的浪费,又能把结点关系理得特别清楚
九、什么是二叉查找树
二叉查找树,英文名为 Binary Search Tree,简称BST,又名二叉排序树、二叉搜索树。
二叉查找树本身就是一棵二叉树,它可以是一棵空树
当二叉查找树不为空时,必须满足以下三个条件:
- 非空左子树的结点的
key小于其根结点的key - 非空右子树的结点的
key大于其根结点的key - 左子树和右子树本身也是个二叉查找树
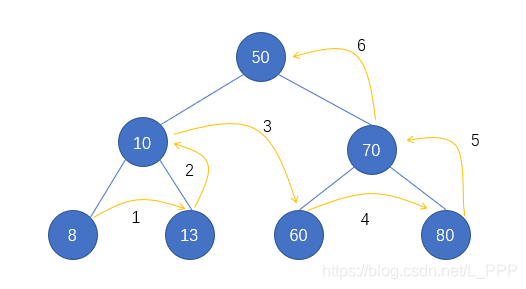
我们可以先一个例子来体会一下这三个条件,如图

首先根结点的 key 为 50 ,其左子结点为 10 小于 50,符合第一个条件 ;其右子结点为 70 大于 50,符合第二个条件
再来看 结点10,其左子结点为 8 小于 10,符合第一个条件 ;其右子结点为 13 大于 10,符合第二个条件
同理,结点70 也是符合的,因此就符合了第三个条件
总结一下呢,就是以下几条结论:
- 左边的结点永远比根结点以及右边的结点小
- 右边的结点永远比根结点已经左边的结点大
所以,接下来我们再来看几个例子,判断一下哪些时二叉查找树,哪些不是

这不是一个二叉查找树,因为 结点7 在右侧,比其根结点 8 要小,所以不符合条件。正确的位置应该是处于 结点8 的左子树位置
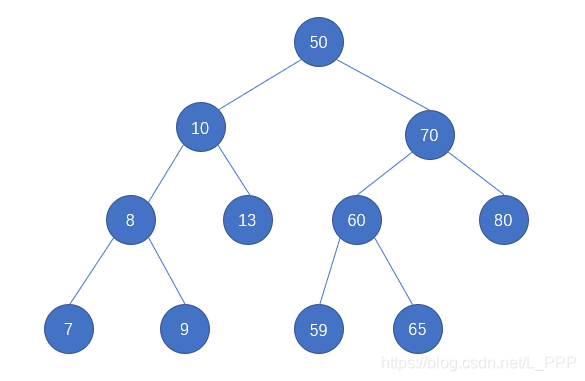
这是一个二叉查找树
十、树的遍历
以上给出的树结构的图都是我们布局好的非常美观的样子,但在程序里,树结构是非常抽象的,因此我们可以通过遍历全部结点的方式,将整个树结构展现出来
树的遍历一共分成三种,分别是 先序遍历 、中序遍历 、后序遍历
(1)先序遍历
先序遍历: 访问根结点 => 访问左子树 => 访问右子树。在访问左子树或右子树的时候,仍是按照这个规则继续访问。
我们来看一个简单的例子,如图,对其进行先序遍历

第一步: 先访问根结点 50 ,再访问左子树,最后访问右子树,如图
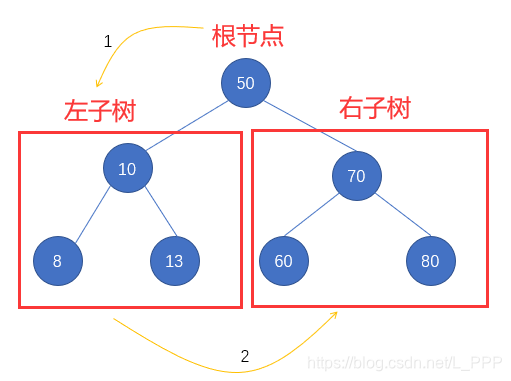
此时我们记录一下访问的过程,即 50 左子树10 右子树70
第二步: 左子树10 也需要按照先序遍历的步骤进行,所以先访问 左子树10 中的根节点 10,再遍历其左子树,最后遍历其右子树,如图
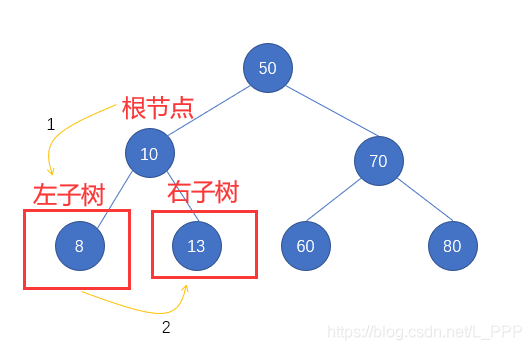
因为 结点10 的左右子树都属于叶子结点了,即没有任何的子结点了,所需就无需对其进行遍历了
我们接着第一步中的结果进行记录,即 50 10 8 13 右子树70
第三步: 最后还剩个 右子树70 没有遍历了,那么同理,先访问其根结点 70,再遍历其左子树,最后遍历其右子树,如图
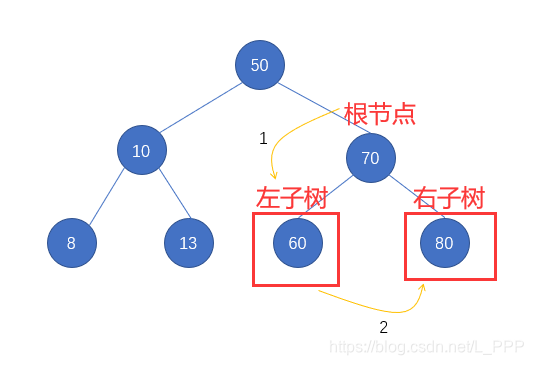
因为 结点70 的左右子树也都属于叶子结点了,所以也没有必要对其进行遍历了,直接获取该结点即可
我们接着第二步的结果进行记录,即 50 10 8 13 70 60 80
好了,到此位置,一个先序遍历的结果就出来了,我们来总结一下它的全部访问过程,如图
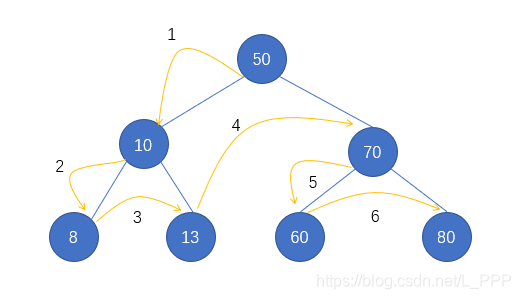
(2)中序遍历
中序遍历: 访问左子树 => 访问根结点 => 访问右子树。在访问左子树或右子树的时候,仍是按照这个规则继续访问。
我们来看一个简单的例子,如图,对其进行中序遍历

第一步: 先遍历 左子树10,再访问根结点 50,最后遍历右子树 70,如图

此时我们记录一下访问的过程,即 左子树10 50 右子树70
第二步: 左子树10 也需要按照中序遍历的步骤进行,所以先遍历 左子树10 中的左子树,再访问其根节点 10,最后遍历其右子树,如图
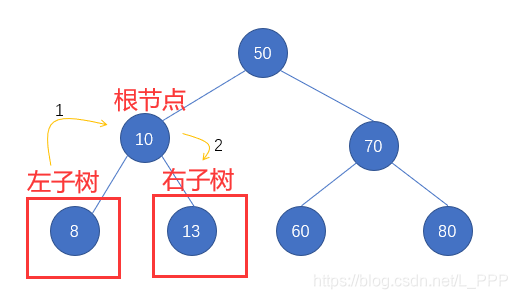
因为 结点10 的左右子树都属于叶子结点了,即没有任何的子结点了,所需就无需对其进行遍历了
我们接着第一步中的结果进行记录,即 8 10 13 50 右子树70
第三步: 最后还剩个 右子树70 没有遍历了,那么同理,先遍历 右子树70 的左子树,再访问其根结点 70,最后遍历其右子树,如图
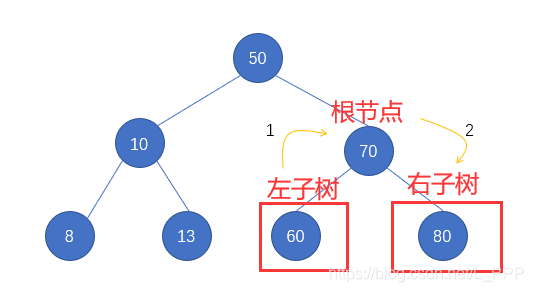
因为 结点70 的左右子树也都属于叶子结点了,所以也没有必要对其进行遍历了,直接获取该结点即可
我们接着第二步的结果进行记录,即 8 10 13 50 60 70 80
好了,到此位置,一个中序遍历的结果就出来了,我们来总结一下它的全部访问过程,如图
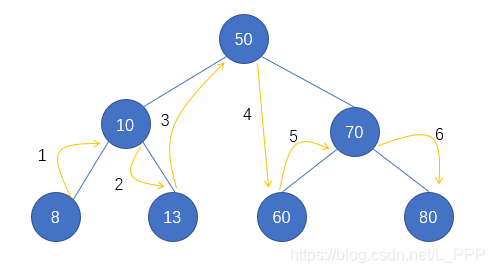
(3)后序遍历
后序遍历: 访问左子树 => 访问右子树 => 访问根结点 。在访问左子树或右子树的时候,仍是按照这个规则继续访问。
我们来看一个简单的例子,如图,对其进行后序遍历
第一步: 先遍历 左子树10,再遍历右子树 70,最后访问根结点 50,如图

此时我们记录一下访问的过程,即 左子树10 右子树70 50
第二步: 左子树10 也需要按照后序遍历的步骤进行,所以先遍历 左子树10 中的左子树,再遍历其右子树,最后再访问其根节点 10,如图

因为 结点10 的左右子树都属于叶子结点了,即没有任何的子结点了,所需就无需对其进行遍历了
我们接着第一步中的结果进行记录,即 8 13 10 右子树70 50
第三步: 最后还剩个 右子树70 没有遍历了,那么同理,先遍历 右子树70 的左子树,再遍历其右子树,最后访问其根结点 70,如图

因为 结点70 的左右子树也都属于叶子结点了,所以也没有必要对其进行遍历了,直接获取该结点即可
我们接着第二步的结果进行记录,即 8 13 10 60 80 70 50
好了,到此位置,一个后序遍历的结果就出来了,我们来总结一下它的全部访问过程,如图
十一、二叉查找树的方法
在封装二叉查找树之前,我们还是先来看一下二叉查找树常见的方法右哪些吧
| 方法 | 作用 |
|---|---|
| insert() | 向二叉查找树插入数据 |
| preOrder() | 先序遍历二叉查找树,并返回结果 |
| inOrder() | 中序遍历二叉查找树,并返回结果 |
| postOrder() | 后序遍历二叉查找树,并返回结果 |
| getMax() | 返回二叉查找树中的最大值 |
| getMin() | 返回二叉查找树中的最小值 |
| search() | 查找二叉查找树中的某个值 |
| remove() | 移除某个值 |
十二、用代码实现二叉查找树
前提:
- 代码中会用到大量的递归思想,请还没了解过递归的小伙伴自行了解一下
- 部分方法会通过再封装一个内部函数来实现,请认真理解
(1)创建一个构造函数
首先创建一个大的构造函数,用于存放二叉查找树的一些属性和方法。
function BinarySearchTree() {
// 属性
this.root = null
}
二叉查找树的属性最主要的就是 root ,用于指向树的根节点
(2)创建结点构造函数
因为我们准备通过链表来实现二叉查找树,所以我们需要先在内部封装一个结点的构造函数
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
}
一个结点包括的内容有 键 、值 、左子结点 、右子结点,分别对应的 key 、value 、left 、right
(3)实现insert()方法
insert()方法就是将一个数据插入到二叉查找树中合适的位置。该方法接收两个参数,即 key 、value
实现思路:
- 调用内部结点构造函数,并把参数
key和value传入,生成一个结点对象node - 判断二叉查找树是否右根结点,即判断是否为空,若为空,则直接将
node作为二叉查找树的根结点,即将node赋值给root属性 - 若不为空,则遍历整个二叉查找树,用
node.key与遍历到的结点的key值进行比对,最终找到合适的位置进行插入
思路看着略微复杂,我做了动图方便大家理解,如图
- 当二叉查找树为空时

- 当二叉查找树不为空时

这里我选择用递归的方式来遍历整个二叉查找树,因此我会再额外封装一个用于递归内部调用的函数 insertNode ,给其传入两个参数,第一个参数是当前遍历到的结点 ; 第二个参数是我们要插入的结点
先来看下代码吧
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 插入数据
BinarySearchTree.prototype.insert = function(key, value = null) {
// 1. 创建结点
let node = new Node(key, value)
// 2. 判断根结点是否存在
// 2.1 不存在
if(!this.root) {
this.root = node
return;
}
// 2.2 存在
this.insertNode(this.root, node)
}
// 插入结点函数(内部)
BinarySearchTree.prototype.insertNode = function(oldNode, newNode) {
// 1. 判断我们插入的数据的 key是否大于当前遍历结点的 key
// 1.1 插入数据的 key 大于当前遍历结点的 key
if(newNode.key < oldNode.key) {
// 1.1.1 判断当前遍历结点的左结点是否为空
// 1.1.1.1 为空
if(oldNode.left === null) {
oldNode.left = newNode
}
// 1.1.1.2 不为空
else {
this.insertNode(oldNode.left, newNode)
}
}
// 1.2 插入数据的 key 小于当前遍历结点的 key
else {
// 1.2.1 判断当前遍历结点的右结点是否为空
// 1.2.1.1 为空
if(oldNode.right === null) {
oldNode.right = newNode
}
// 1.2.1.2 不为空
else {
this.insertNode(oldNode.right, newNode)
}
}
}
}
在 insert() 方法中,若二叉查找树不为空,我们就调用 insertNode() 内部方法进行递归调用,并先把 root 和 我们新创建的结点 node 传过去当成参数 , 即表示用需要插入的结点先和根节点进行比较,然后慢慢比对下去,找到属于自己的位置插入
我在代码上都标注了很详细的注解,大家可以消化消化
我们来使用一下该方法
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
console.log(bst.root)
因为这里我们还没有封装遍历的函数,因此可以靠浏览器的打印来查看二叉查找树是否正确,结果如下

首先,根节点为 50,然后根节点的左子节点为 10,右子结点为 70

然后看到 结点10 的左子结点是 5,右子结点是 15

最后,结点70 没有自己的左右子结点
总结一下,当前的二叉树如下图
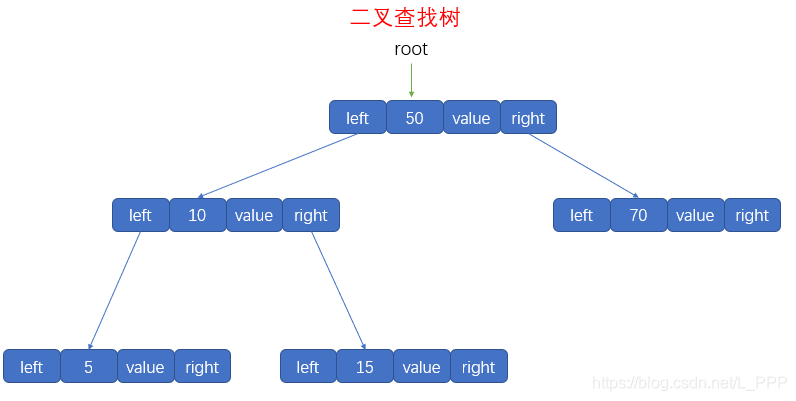
判断一下,这个结果是正确的,这确实是一个二叉查找树,所以我们的 insert()方法就封装好啦
(4)实现preOrder()方法
preOrder()方法就是通过先序遍历的方式遍历整个二叉查找树,并返回遍历结果。该方法接收一个回调函数 handle 作为参数, 用于在遍历过程中执行某些操作
实现思路:
- 从根结点开始,按照
访问根结点 => 访问左子树 => 访问右子树的顺序对各个结点进行访问 - 访问到结点时,执行回调函数
handle,并将访问到的结点的key作为参数传入
因为上边已经详细将结果先序遍历的全过程了,因此我们直接来看代码
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 先序遍历并返回结果(外部函数)
BinarySearchTree.prototype.preOrder = function(handle) {
// 从整棵二叉查找树的根节点开始遍历
this.preOrderNodes(this.root, handle)
}
// 以先序遍历的方式遍历整个树(内部函数)
BinarySearchTree.prototype.preOrderNodes = function(node, handle) {
if(node !== null) {
// 将根结点的 key传给回调函数处理
handle(node.key)
// 遍历左子树
this.preOrderNodes(node.left, handle)
// 遍历右子树
this.preOrderNodes(node.right, handle)
}
}
}
我们来使用一下该方法,并详细体会一下递归调用的过程是不是跟我们前面分析的先序遍历的思想一样
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 50 10 5 15 70
首先二叉查找树是这样的

-
刚开始我们从整棵树的根节点
root开始遍历,先记录root的key值,即50;然后遍历root的左子树,因此把root.left作为下一次调用preOrderNodes()方法的根结点 -
然后记录一下
结点10,即50 10,然后我们又要继续遍历结点10的左子树,所以就把结点10.left作为下一次调用preOrderNodes()方法的根结点 -
此时访问到了
结点5,并记录一下50 10 5,再下一次就是遍历结点5的左右子树,但因为结点5的左右子树都为null,所以在调用preOrderNodes()方法时不进行任何操作。到此为止,结点10的左子树已经全部遍历完毕,接着就要遍历其右子树,因此把结点10.right作为下一次调用preOrderNodes()方法的根结点 -
此时就访问到了
结点15,并记录一下50 10 5 15,再下一次就是遍历结点15的左右子树,但因为结点15的左右子树都为null,所以在调用preOrderNodes()方法时不进行任何操作。到此为止,结点50的左子树已经全部遍历完毕了,接着就要遍历其右子树,因此把结点50.right作为下一次调用preOrderNodes()方法的根结点 -
此时就访问到了
结点70,并记录一下50 10 5 15 70,再下一次就是遍历结点15的左右子树,但因为结点15的左右子树都为null,所以在调用preOrderNodes()方法时不进行任何操作。到此为止,结点50的右子树也全部遍历完毕了。 -
因为整棵树的根节点的左右子树都遍历完了,所以先序遍历的操作也就完成了,最终结果就为
50 10 5 15 70
(5)实现inOrder()方法
inOrder()方法就是通过中序遍历的方式遍历整个二叉查找树,并返回遍历结果。该方法无需传入参数
实现思路:
- 从根结点开始,按照
访问左子树 => 访问根节点 => 访问右子树的顺序对各个结点进行访问 - 访问到结点时,执行回调函数
handle,并将访问到的结点的key作为参数传入
因为上边已经详细将结果中序遍历的全过程了,因此我们直接来看代码
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 中序遍历并返回结果(外部函数)
BinarySearchTree.prototype.inOrder = function(handle) {
// 从二叉查找树的根结点开始遍历
this.inOrderNodes(this.root, handle)
}
// 以中序遍历的方式遍历整个树(内部函数)
BinarySearchTree.prototype.inOrderNodes = function(node, handle) {
if(node !== null) {
// 遍历左子树
this.inOrderNodes(node.left, handle)
// 将根结点的 key传给回调函数处理
handle(node.key)
// 遍历右子树
this.inOrderNodes(node.right, handle)
}
}
}
因为树结构的三种遍历方式思想都一样,只不过是遍历的顺序有所差别,这里我就不再花大篇幅来讲解整个遍历过程了,直接来使用一下代码,核对一下结果是否准确
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
let str = ''
bst.inOrder(function(key) {
str += `${key} `
})
console.log(str) // 5 10 15 50 70
验证了一下,结果是正确的
(6)实现postOrder()方法
postOrder()方法就是通过后序遍历的方式遍历整个二叉查找树,并返回遍历结果。该方法无需传入参数
实现思路:
- 从根结点开始,按照
访问左子树 => 访问右子树 => 访问根结点的顺序对各个结点进行访问 - 访问到结点时,执行回调函数
handle,并将访问到的结点的key作为参数传入
因为上边已经详细将结果后序遍历的全过程了,因此我们直接来看代码
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 后序遍历并返回结果(外部函数)
BinarySearchTree.prototype.postOrder = function(handle) {
// 从二叉查找树的根结点开始遍历
this.postOrderNodes(this.root, handle)
}
// 以后序遍历的方式遍历整个树(内部函数)
BinarySearchTree.prototype.postOrderNodes = function(node, handle) {
if(node !== null) {
// 访问左子树
this.postOrderNodes(node.left, handle)
// 访问右子树
this.postOrderNodes(node.right, handle)
// 将根结点的 key传给回调函数处理
handle(node.key)
}
}
}
因为树结构的三种遍历方式思想都一样,只不过是遍历的顺序有所差别,这里我就不再花大篇幅来讲解整个遍历过程了,直接来使用一下代码,核对一下结果是否准确
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
let str = ''
bst.postOrder(function(key) {
str += `${key} `
})
console.log(str) // 5 15 10 70 50
验证了一下,结果是正确的
(7)实现getMax()方法
getMax()方法就是找到二叉查找树中 key 值最大的结点,并返回该结点对象
实现思路: 该方法思路比较简单,因为二叉查找树越大的值都是往右走的,即 key值较大的结点都是其父结点的右子结点,因此我们可以从整个二叉查找树的根节点开始,一直向右查找,即 node.right,直到 node.right === null,该结点就为这个二叉查找树中 key值最大的结点
我们来直接看一下代码吧
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 获取二叉树中的最大值
BinarySearchTree.prototype.getMax = function() {
// 从根结点开始遍历
let node = this.root
// 一直向二叉查找树的的右边遍历,直到结点没有右子结点
while(node.right !== null) {
node = node.right
}
// 返回 key值最大的结点对象
return node
}
}
我们来使用一下该方法
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
bst.insert(60)
bst.insert(80)
bst.insert(13)
bst.insert(12)
bst.insert(14)
bst.insert(19)
bst.insert(20)
bst.insert(16)
bst.insert(17)
console.log(bst.getMax())
// Node { key: 80, value: null, right: null, left: null }
可以看到,最终结果确实返回了 key值最大的结点,为 结点80
(8)实现getMin()方法
getMin()方法就是找到二叉查找树中 key 值最小的结点,并返回该结点对象
实现思路: 该方法思路比较简单,因为二叉查找树越小的值都是往左走的,即 key值较小的结点都是其父结点的左子结点,因此我们可以从整个二叉查找树的根节点开始,一直向左查找,即 node.left,直到 node.left === null,该结点就为这个二叉查找树中 key值最小的结点
我们来直接看一下代码吧
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 获取二叉树中的最小值
BinarySearchTree.prototype.getMin = function() {
// 从二叉查找树的根结点开始遍历
let node = this.root
// 一直向二叉查找树的左边遍历,直到结点没有左子结点
while(node.left !== null) {
node = node.left
}
// 返回 key值最小的结点对象
return node
}
}
我们来使用一下该方法
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
bst.insert(60)
bst.insert(80)
bst.insert(13)
bst.insert(12)
bst.insert(14)
bst.insert(19)
bst.insert(20)
bst.insert(16)
bst.insert(17)
console.log(bst.getMin())
// Node { key: 5, value: null, right: null, left: null }
可以看到,最终结果确实返回了 key值最小的结点,为 结点5
(9)实现search()方法
search()方法就是查找二叉查找树中指定的 key对应的结点的 value 值。该方法接收一个参数,即需要查找的结点的 key 值
实现思路: 从二叉查找树的根节点 root 开始遍历,用我们的参数 key1 与遍历到的结点的 key2 进行比较,若 key1 > key2,则向右继续遍历 ;若 key1 < key2,则向左继续遍历 ;若 key1 === key2,则返回该结点的 value 值 ;若遍历到最后,找不到任何结点了,则返回 false
我们来看一下实现代码
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 查找指定的 key对应的数据
BinarySearchTree.prototype.search = function(key) {
// 1. 从二叉查找树的根结点开始遍历
let node = this.root
// 2. 一直与遍历到的结点的 key值进行比较
while(node !== null) {
// 查找的 key值大于当前结点 key值
if(key > node.key) {
node = node.right
}
// 查找的 key值小于当前结点 key值
else if(key < node.key) {
node = node.left
}
// 查找到对应 key值的结点
else {
return node.value
}
}
// 未找到对应 key值的结点
return false
}
}
因为这个方法要返回结点的 value 值,因此这里我们就给每个结点赋值一定的 value
let bst = new BinarySearchTree()
bst.insert(50, '我是结点50')
bst.insert(10, '我是结点10')
bst.insert(70, '我是结点70')
bst.insert(5, '我是结点5')
bst.insert(15, '我是结点15')
bst.insert(60, '我是结点60')
bst.insert(80, '我是结点80')
bst.insert(13, '我是结点13')
bst.insert(12, '我是结点12')
bst.insert(14, '我是结点14')
bst.insert(19, '我是结点19')
bst.insert(20, '我是结点20')
bst.insert(16, '我是结点16')
bst.insert(17, '我是结点17')
console.log(bst.search(13)) // 我是结点13
console.log(bst.search(50)) // 我是结点50
console.log(bst.search(99)) // false
(10)实现remove()方法
remove()方法就是用来移除二叉查找树中指定 key 值的结点。该方法需要接收一个参数 key
总的来说,在二叉查找树的封装中,我认为 remove() 方法应该算是需要考虑情况最最最最最多的,并且需要一定技巧的方法,因此我们先不着急封装,先来观察二叉查找树,如图
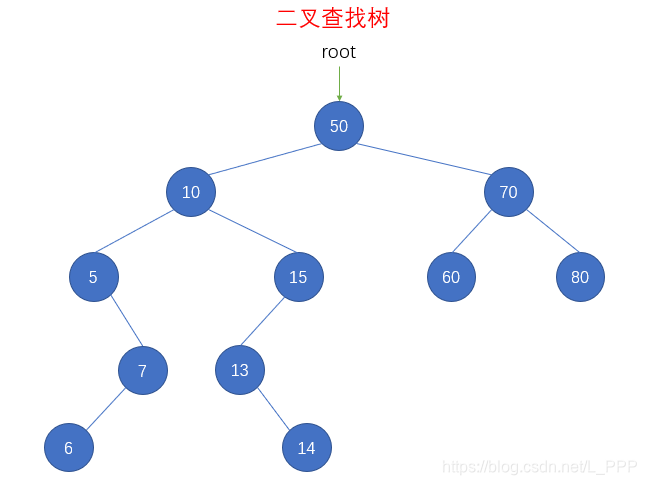
放眼望去,我们可以把结点先总的分成三种类型:
- 叶子结点(没有子结点)
- 只有一个子结点(左子结点或右子结点)
- 有两个子结点
同时,这三种情况就是我们在封装 remove() 方法时要考虑的三种情况,我们来分别研究一下
- 删除的结点为叶子结点
假设我们要删除 结点14 ,因为该结点为叶子结点,后面没有其它结点,所以直接删除它不会对后续结点造成影响,即将 结点14 的父节点 结点13 的右子结点设置为 null ,如图

- 删除的结点只有一个子结点
假设我们要删除的结点为 结点5 ,该结点只有一个右子结点,那么我们只需要用 结点5 的右子结点来代替 结点5 原本的位置,因为 结点5 下面的所有结点肯定都小于 结点10,因此我们只需要将 结点10 的左子结点设置成 结点7 ,如图

同样的,如果我们要删除 结点15 ,也是只需要用其子结点来代替其原来的位置即可,如图

- 删除的结点有两个子结点
假设我们要删除的结点为 结点10 ,它有两个子结点,且子结点后面还有好多结点。当 结点10 被移除以后,该位置上应该有一个比其左子结点 结点5 以及后面所有结点还要大,同时比其右子结点 结点15 以及后面所有结点还要小的结点,这样的结点怎么找呢?
这里我给大家一个思路,此时我们有两种选择:
-
第一种选择就是去
结点10的左子树里找,找到左子树里key值最大的一个结点,在本例中,最大的结点肯定就是结点7了,然后我们用结点7代替结点10的位置,这样就能保证该位置上结点的key值大于左子树里所有结点的key值,又能保证小于右子树里所有结点的key值了。同时我们不能忘记了,结点7也有它自己的子结点,但能保证的是它一定没有右子结点,因为如果结点7还有右子结点,那么结点7就不是最大的结点了,所以我们只需要考虑它有无左子结点即可。

-
第二种选择自然就是去
结点10的右子树里去找了,找到右子树里key值最小的一个结点,在本例中,最小的结点肯定是结点13了,然后我们也一样的用结点13代替结点10的位置,这样就能保证该位置上结点的key值大于左子树里所有结点的key值,又能保证小于右子树里所有结点的key值了。至于结点13的子结点如何处理,想必应该不用我再过多重复了吧

这就是 remove() 方法要考虑的三种情况了,接下来我们来讲解一下整个方法的实现思路
实现思路:
- 先遍历整个二叉查找树,找到我们要删除的结点
node,同时创建变量parent和direction分别记录结点node的父节点 以及结点node属于其父节点的左结点还是右结点。若没有遍历到我们要删除的结点,则返回false - 若遍历到了要删除的结点
node,则按上面提到三种情况分析结点node的类型,然后做出相应的处理,需要注意的是,无论分析哪种类型结点,我们还需要多做一步判断,那就是被删除结点是否为根节点root
好了,前面铺垫了那么多,现在我们来写一下代码吧,这里先申明一下,在面对被删除结点右两个子结点时,我选用的是我上面提到的第二种选择
function BinarySearchTree() {
// 属性
this.root = null
// 结点构造函数
function Node(key, value) {
this.key = key
this.value = value
this.right = null
this.left = null
}
// 删除指定 key的数据
BinarySearchTree.prototype.remove = function(key) {
let node = this.root
let parent = null
let direction = ''
// 1. 找到需要被删除的节点
while(node !== null) {
if(key < node.key) {
parent = node
direction = 'left'
node = node.left
} else if(key > node.key) {
parent = node
direction = 'right'
node = node.right
} else {
break;
}
}
// 1.1 未找到对应节点,删除失败
if(node === null) return false;
// 1.2 找到对应节点
// 2. 判断节点类型(叶子节点、只有一个子节点、有两个子节点)
// 2.1 节点类型为叶子节点
if(node.left === null && node.right === null) {
if(node === this.root) {
this.root = null
} else {
parent[direction] = null
}
}
// 2.2.1 节点只有一个右子节点
else if(node.left === null) {
if(node === this.root) {
this.root = this.root.right
} else {
parent[direction] = node.right
}
}
// 2.2.2 节点只有一个左子节点
else if(node.right === null) {
if(node === this.root) {
this.root = this.root.left
} else {
parent[direction] = node.left
}
}
// 2.3 节点有两个子节点
else {
let minNode = node.right
let minNode_parent = node
// 2.3.1 找到被删除节点右子节点的子孙节点中最小的节点
while(minNode.left !== null) {
minNode_parent = minNode
minNode = minNode.left
}
// 2.3.2 判断 minNode是否有右子节点
// 2.3.2.1 无右子节点
if(minNode.right === null) {
if(node === this.root) {
this.root = minNode
} else {
parent[direction] = minNode
}
minNode.left = node.left
minNode.right = node.right
minNode_parent.left = null
}
// 2.3.2.2 有右子节点
else {
if(node === this.root) {
this.root = minNode
} else {
parent[direction] = minNode
}
minNode_parent.left = minNode.right
minNode.left = node.left
minNode.right = node.right
}
}
}
}
这里我们仍然用上面提到的那个例子,因此先用 insert() 方法插入相应的结点
let bst = new BinarySearchTree()
bst.insert(50)
bst.insert(10)
bst.insert(70)
bst.insert(5)
bst.insert(15)
bst.insert(7)
bst.insert(6)
bst.insert(13)
bst.insert(14)
bst.insert(60)
bst.insert(80)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 50 10 5 7 6 15 13 14 70 60 80
我们采用先序遍历的方式,先验证二叉查找树的初始状态,此时的二叉树查找树如下图
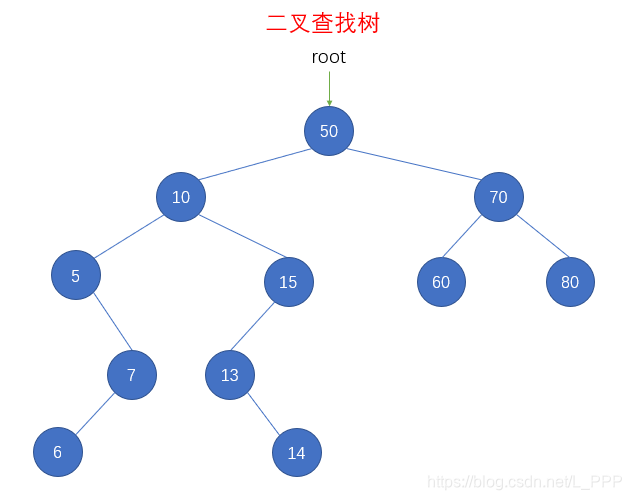
- 删除结点6(叶子节点)
bst.remove(6)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 50 10 5 7 15 13 14 70 60 80
在删除了 结点6 以后,先序遍历输出的结果为 50 10 5 7 15 13 14 70 60 80 ,还原成二叉查找树如下图
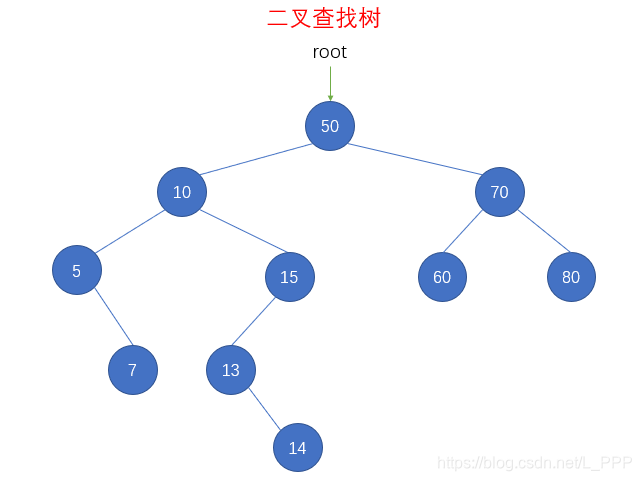
- 删除结点15(只有一个子结点)
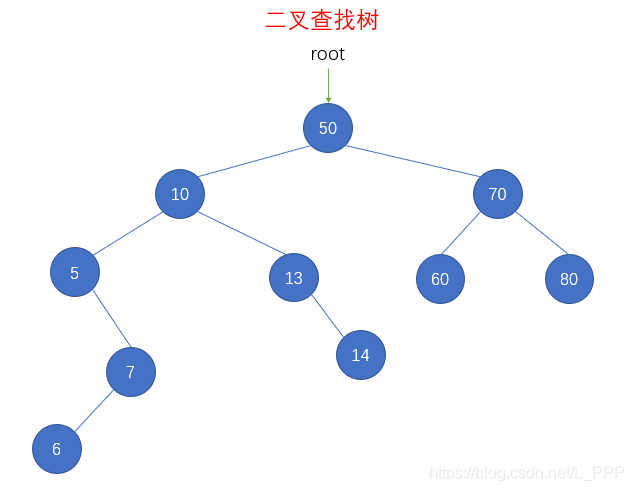
bst.remove(15)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 50 10 5 7 6 13 14 70 60 80
在删除了 结点15 以后,先序遍历输出的结果为 50 10 5 7 6 13 14 70 60 80 ,还原成二叉查找树如下图
- 删除结点10(有两个子结点)
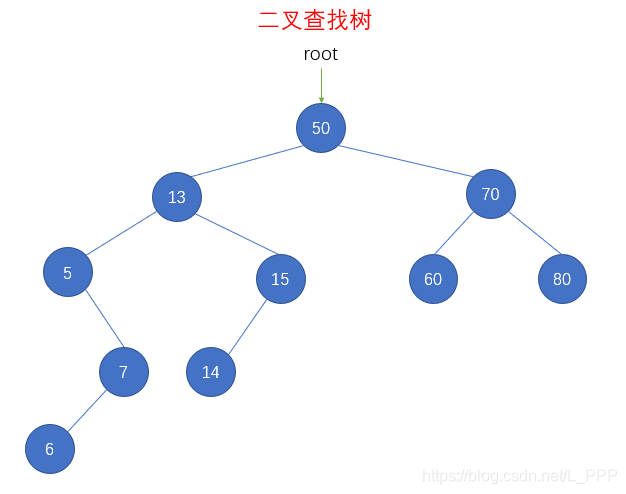
bst.remove(10)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 50 13 5 7 6 15 14 70 60 80
在删除了 结点10 以后,先序遍历输出的结果为 50 13 5 7 6 15 14 70 60 80 ,还原成二叉查找树如下图
- 删除根节点50(有两个子结点)
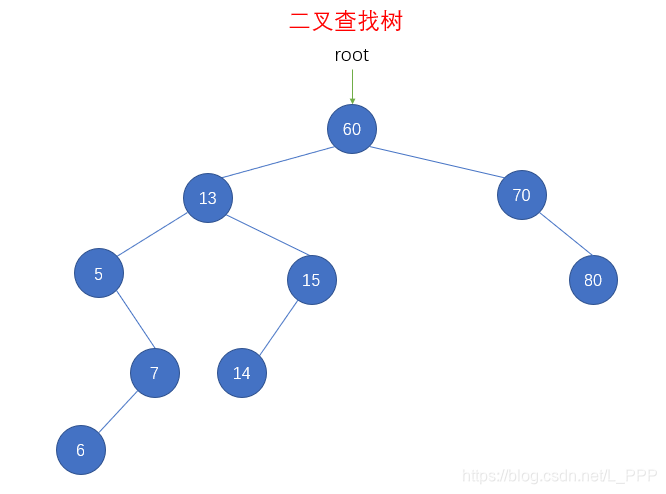
bst.remove(50)
let str = ''
bst.preOrder(function(key) {
str += `${key} `
})
console.log(str) // 60 10 5 7 6 15 13 14 70 80
在删除了 结点50 以后,先序遍历输出的结果为 60 10 5 7 6 15 13 14 70 80 ,还原成二叉查找树如下图
十三、结束语
二叉查找树的讲解就到这里了,希望大家对二叉查找树有了更深一层的理解。下一篇文章我将讲解一下红黑树。
大家可以关注我,之后我还会一直更新别的数据结构与算法的文章来供大家学习,并且我会把这些文章放到【数据结构与算法】这个专栏里,供大家学习使用。
然后大家可以关注一下我的微信公众号:前端印象,等这个专栏的文章完结以后,我会把每种数据结构和算法的笔记放到公众号上,大家可以去那获取。
或者也可以去我的github上获取完整代码,欢迎大家点个Star
我是Lpyexplore,创作不易,喜欢的加个关注,点个收藏,给个赞~ 带你们在Python爬虫的过程中学习Web前端
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐