
大数据智能推荐系统原理介绍
日期: 2019-03-07 分类: 跨站数据 517次阅读
一.什么是推荐系统:
通过算法分析用户喜欢什么,再把那些分析出来用户会喜欢的东西推荐给用户。
二.为什么要用推荐系统:
主要有以下三点好处:
1.用户:得到想要的物品
2.平台:获得更多的流量和收入
3.内容提供商:提高售卖效率
据了解,亚马逊有20%~30%的销售来自于推荐系统。
大拿语录:
 ——杰夫.贝佐斯
——杰夫.贝佐斯
三.我们该如何推荐:
刚刚说到是通过算法分析用户喜欢什么,那么都有哪些算法呢?是如何分析的呢?
主要可分为以下几点:
1.基于流行度的推荐
2.基于好友推荐
3.基于人口统计学的推荐
4.基于内容的推荐算法(content based—简称CB)
5.基于协同过滤的推荐算法(collaborative filtering—简称CF)
6.混合推荐机制
别被吓到,原理很简单,下面依次介绍:
1.基于流行度的推荐:
根据PV、UV、日均PV或收藏数、分享率等数据来按某种热度排序来推荐给用户。
优点:
简单,适用于刚注册的新用户,无用户“冷启动”问题。
缺点:
无法针对用户提供个性化推荐。
举个栗子:
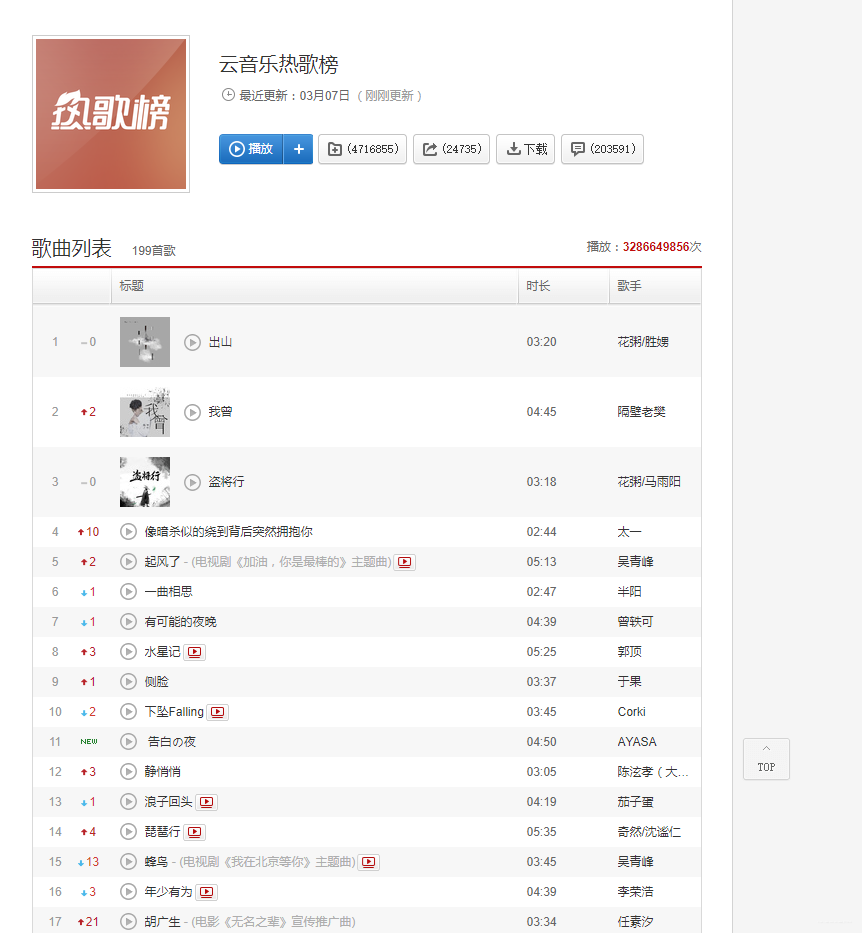
基于这种算法可做一些优化:
比如加入用户分群的流行度排序,把热榜上的摇滚歌曲分给爱听摇滚的用户,把民谣热歌推荐给爱听民谣的用户。。。。
2.基于好友推荐:
把你好朋友喜欢的东西推荐给你
据心理学上说,**你身边人推荐给你的东西甚至比一些权威人物的建议更容易让你接受!**我身边不少栗子确实是这样的,我就是栗子本栗了。
举个栗子:
3.基于人口统计学的推荐:
简单根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的物品推荐给当前用户。
优点:
(1).不使用当前用户对物品的喜好历史,数据没有“冷启动”问题。
(2).不依赖于物品本身的数据。
缺点:
只考虑用户本身的特征,计算用户相似度,虽有一定个性化,但还不够精准。
4.基于内容的推荐算法(content basedI:CB):
根据用户过去喜欢的产品,为用户推荐和他过去喜欢产品相似的物品。
CB过程一般包括三步:
(1).Item Presentation:为每个item抽取出一些特征(也就是item的content)来表示此item。
描述item的属性分为两种:
1.结构化属性:例如身高、学历、年龄。。。
2.非结构化属性:例如文章的内容等。。。
(2).profile learning:利用一个用户过去喜欢(及不喜欢)的item的特征数据,来学习出用户的喜好特征。
方法:通过用户过去的喜好,为他产生一个模型,根据这个模型判断用户是否会喜欢一个新的item。
首先找到用户已经评判过并与此新item最相似的k个item,然后根据用户对这k个item喜好程度判断对此新item的喜好程度。
相似度计算:
- 对于结构化数据:欧几里得距离。
- 对于向量空间模型(VSM)来表示item的话,使用cosine
(3). Recommendation Generation:通过比较上一步得到的用户profile与候选item的特征,为此用户推荐一组相关性最大的item。
基于内容推荐,有两类:非个性化、个性化,不同场景选择不同的推荐方式
非个性化
实现方案:
-
对元数据建立正排表:jieba分词,Tf-idf抽取每个item的特征及分数
例: item1—>token1:score,token2:score, token3:score ,item2—>token2:score,token3:score, token6:score -
建立倒排表入库:token1–>item1:score, token2–>item1:score,item2:score ,token3item1:score,item2:score ……
-
根据用户输入itemA,分词形成token:score,用token查询倒排表,进行相关性计算,乘倒排表中的item:score,再排序,最终形成itemA—>itemB:score1,itemC:score2
-
取topN推荐给用户
个性化
实现方案:
在上述基础上++用户画像
用户画像:
1、历史观看、收藏、购买记录
2、用户注册数据,年龄、性别等
3、社交信息:关系数据
解决马太效应—>多样性差问题的方法—试探:
例:5个推荐位,偶尔在一个推荐位随机选一个做试探(其他行业、频道)
3.基于协同过滤的推荐算法(collaborative filtering:CF)
协同算法可分为:
•User-Based CF(基于用户相似度的协同过滤)
•Item-Based CF(基于物品相似度的协同过滤)
(1).基于用户的协同过滤算法(User-Based CF)
当用户A需要个性化推荐时,可以找到和他兴趣相似的用户样本B,然后把B喜欢的且A没有听说过的物品推荐给A。
举个栗子:
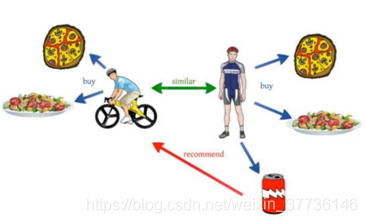
步骤:
- 发现兴趣相似用户:通常用jaccard公式或者余弦相似度计算两个用户的相似度(具体算法后续会发文详细介绍)。
- 推荐物品:
首先要从矩阵中找出与目标用户U最相似的K个用户,用集合S(K,U)表示,将S中用户喜欢的物品全部提取出来,并去除U已经喜欢的物品。对每个候选物品i,用户U对它的感兴趣程度进行计算,最终按得分排序,取前几个物品。
特点:
在用户的历史偏好的数据上计算用户的相似度。
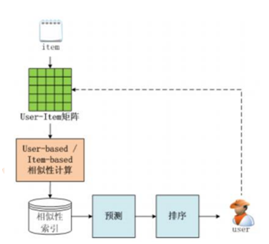
优点:
1.充分利用群体智慧
2.推荐精度高于CB
3.利于挖掘隐含的相关性
缺点:- 推荐结果解释性较差
- 对时效性强的item不适用
- 冷启动问题

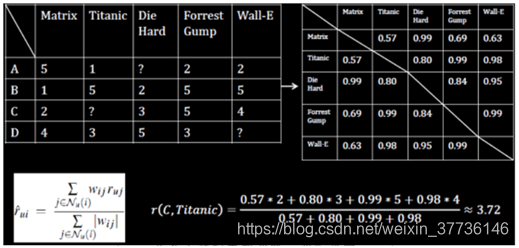
相似度计算(cosine):
例:sim(A&B)
分子:5x1+1x5+0x2+2x5+2x5 = 5 + 5 + 0 + 10 +10 = 30
分母:
|A|:sqrt(5x5 + 1x1 +0x0 + 2x2 + 2x2) = 5.83
|B|: sqrt(1x1 + 5x5+ 2x2 + 5x5 + 5x5)= 8.94
Cosine = 分子/分母 = 30/5.83 x 8.94 = 0.58
(2).基于物品的协同过滤(Item-Based CF)
使用所有用户对物品或信息的偏好,发现物品与物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
特点:
适用于物品个数远小于用户数量、物品的个数和相似度相对比较稳定的业务。
比基于用户的实时性更好一些。
与基于内容的推荐都是基于物品相似度的推荐,但是计算相似度的方法不一样。
基于物品的协同过滤式从用户历史的偏好判断。而基于内容的推荐是基于物品本身的属性特征信息。
补充:工作中如果用户量远大于物品,则建议采用基于物品的协同过滤,反之亦然。如果用户和物品数据都非常庞大,采取随机采样的方式,再权衡好准确度的前提下尽量减少计算量。
(3).基于模型的协同过滤
基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好信息进行预测,计算推荐。
6.混合推荐机制
根据业务实际选择不同推荐策略的组合
以上介绍了几种最常用的推荐策略,后续会发文详细介绍基于Hadoop、Spark的CB、CF具体实现方法。
需强调的是,应结合自身业务灵活制定推荐策略和技术,推荐系统具有高度复杂性,需要持续地进行改进。可能在同一时间内,需要上线不同的推荐算法,做A/B test。根据用户对推荐结果的行为数据,不断对算法进行优化,改进。。
本文参考了一些前辈们的经验,在此表示万分感谢!
如有不足之处请多提宝贵意见!
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐