
SequoiaDB 架构原理
日期: 2020-05-06 分类: 跨站数据 442次阅读
 记录是在数据页内部从后往前按照一个链表串联起来的
记录是在数据页内部从后往前按照一个链表串联起来的
而索引页和数据页完全不一样
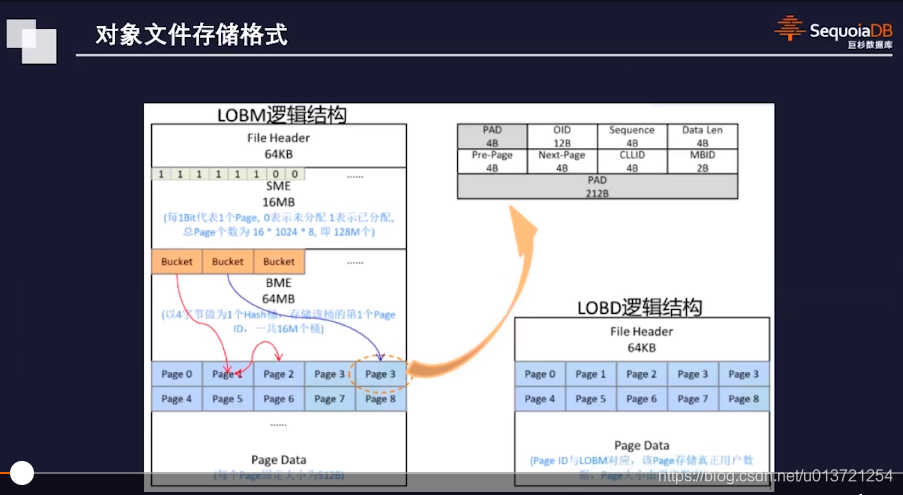
这里发现其实查找数据是不需要查找的,是直接通过Hash算出来的(感觉这里就像是HashMap的思想)
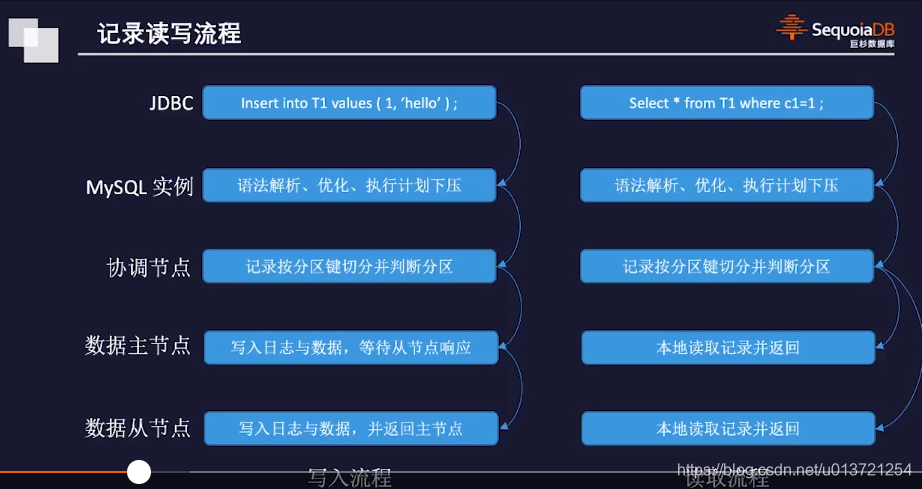
这里就像是Redis的处理,算hash,然后根据分区找到特定的分区。
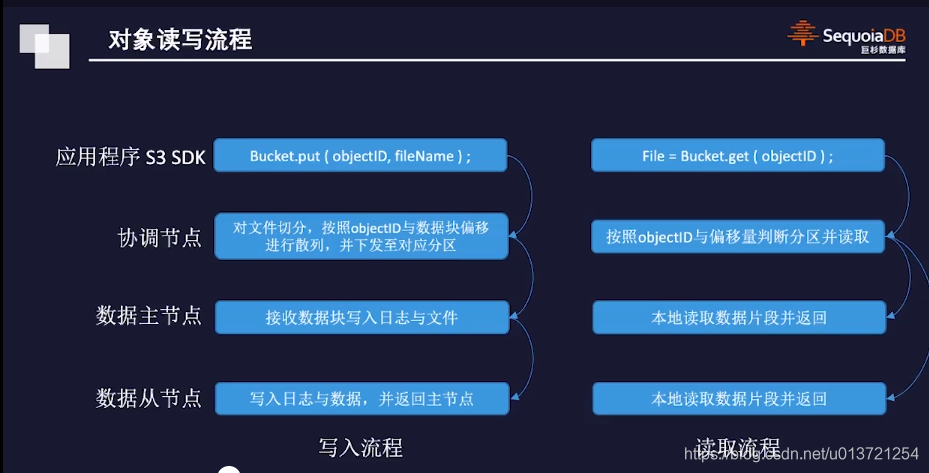
这里是将整个文件打散成多个文件,然后再存放到各个分区,这样就能保住安全性
保住数据的一致性:
 性能分析思路:
性能分析思路:


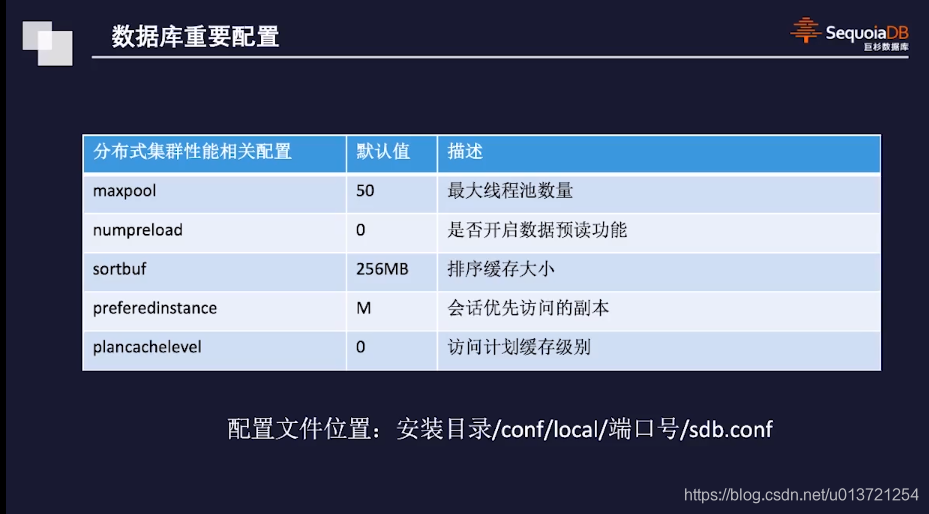
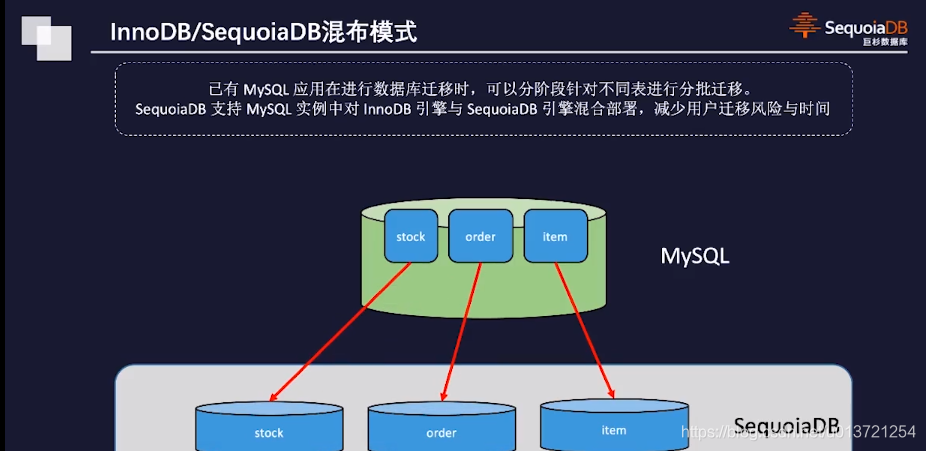
 也可以从SequoiaDB到MySQL
也可以从SequoiaDB到MySQL

除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
标签:数据库
精华推荐