
2020java面试题(含答案)有这一篇就够了
日期: 2020-03-08 分类: 跨站数据 616次阅读
本文摘取了很多其他博客里的内容,同时又融入了一些自己的理解,希望对大家找工作之前的面试准备有所帮助;
一、Spring与SpringMVC
SpringMVC
1.1 简单介绍你所理解的SpringMVC
Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合
1.2 SpringMVC具体流程
- 用户发送请求至前端控制器DispatcherServlet;
- DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle;
- 处理器映射器根据请求url找到具体的处理器(Controoller),生成处理器对象及处理器拦截器(如果有则生成)一起返回给DispatcherServlet;
- DispatcherServlet 调用 HandlerAdapter处理器适配器,经过适配找到并调用具体处理器(Handler,也叫后端控制器,即Controller里的具体方法);
- Handler执行完成返回ModelAndView视图;
- HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
- DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
- ViewResolver解析后返回具体View;
- DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)10. DispatcherServlet响应用户。
1.3 SpringMVC优点
-
可以支持各种视图技术,而不仅仅局限于JSP;
-
与Spring框架集成(如IoC容器、AOP等);
-
清晰的角色分配:前端控制器(dispatcherServlet) , 请求到处理器映射(handlerMapping), 处理器适配器(HandlerAdapter), 视图解析器(ViewResolver)。
-
支持各种请求资源的映射策略。
1.4 主要组件
- 前端控制器 DispatcherServlet(不需要程序员开发)
作用:接收请求、响应结果,相当于转发器,有了DispatcherServlet 就减少了其它组件之间的耦合度。
- 处理器映射器HandlerMapping(不需要程序员开发)
作用:根据请求的URL来查找Handler
- 处理器适配器HandlerAdapter
注意:在编写Handler的时候要按照HandlerAdapter要求的规则去编写,这样适配器HandlerAdapter才可以正确的去执行Handler。
-
处理器Handler(需要程序员开发)
-
视图解析器 ViewResolver(不需要程序员开发)
作用:进行视图的解析,根据视图逻辑名解析成真正的视图(view)
- 视图View(需要程序员开发jsp)
View是一个接口, 它的实现类支持不同的视图类型(jsp,freemarker,pdf等等)
1.5 SpringMVC与struts2的区别
-
springmvc的入口是一个servlet即前端控制器(DispatchServlet),而struts2入口是一个filter过虑器(StrutsPrepareAndExecuteFilter)。
-
springmvc是基于方法开发(一个url对应一个方法),请求参数传递到方法的形参,可以设计为单例或多例(建议单例),struts2是基于类开发,传递参数是通过类的属性,只能设计为多例。
-
Struts采用值栈存储请求和响应的数据,通过OGNL存取数据,springmvc通过参数解析器是将request请求内容解析,并给方法形参赋值,将数据和视图封装成ModelAndView对象,最后又将ModelAndView中的模型数据通过reques域传输到页面。Jsp视图解析器默认使用jstl。
1.6 怎么样设定重定向和转发的
-
转发:在返回值前面加"forward:",譬如"forward:user.do?name=method4"
-
重定向:在返回值前面加"redirect:",譬如"redirect:http://www.baidu.com"
1.7 怎么和AJAX相互调用
通过Jackson框架就可以把Java里面的对象直接转化成Js可以识别的Json对象。具体步骤如下 :
-
加入Jackson.jar
-
在配置文件中配置json的映射
-
在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上@ResponseBody注解。
1.8 解决POST与GET请求中文乱码
1.8.1 post乱码
在web.xml中配置一个CharacterEncodingFilter过滤器,设置成utf-8;
<filter>
<filter-name>CharacterEncodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>utf-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>CharacterEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
1.8.2 get乱码
get请求中文参数出现乱码解决方方式有两个
方式一、
修改tomcat配置文件添加编码与工程编码一致,如下:
<ConnectorURIEncoding="utf-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>
方式二、
对参数进行重新编码:
String userName = new String(request.getParamter("userName").getBytes("ISO8859-1"),"utf-8")
ISO8859-1是tomcat默认编码,需要将tomcat编码后的内容按utf-8编码。
1.9 SpringMVC异常处理
可以将异常抛给Spring框架,由Spring框架来处理;我们只需要配置简单的异常处理器,在异常处理器中添视图页面即可。
1.10 SpringMvc的控制器是不是单例模式,如果是,有什么问题,怎么解决
默认情况下是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性能的,解决方案是在控制器里面不能写字段(即在控制器里不写成员变量)。单例好处:性能好,不用每次请求都创建对象;
1.11 SpringMVC常用的注解有哪些
-
RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。用于类上,则表示类中的所有响应请求的方法都是以该地址作为父路径。
-
RequestBody:注解实现接收http请求的json数据,将json转换为java对象。
-
ResponseBody:注解实现将conreoller方法返回对象转化为json对象响应给客户。
-
@Controller:@Controller 只是定义了一个控制器类,而使用@RequestMapping 注解的方法才是真正处理请求的处理器.
-
@Resource与@Autowired:@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
-
@PathVariable:用于将请求URL中的模板变量映射到功能处理方法的参数上
@RequestMapping(value="/product/{productId}",method = RequestMethod.GET) public String getProduct(@PathVariable("productId") String productId){ System.out.println("Product Id : " + productId); return "hello"; } -
@RequestParam:用于将请求参数区数据映射到功能处理方法的参数上
@RequestMapping("/testRequestParam") public String testRequestParam(@RequestParam("id") int id) { System.out.println("testRequestParam " + id); return "success"; }
1.12 控制器的注解一般用哪个,有没有别的注解可以替代
一般用@Controller注解,也可以使用@RestController,@RestController注解相当于@ResponseBody + @Controller,表示是表现层,除此之外,一般不用别的注解代替
1.13 在拦截请求中,我想拦截get方式提交的方法,怎么配置
可以在@RequestMapping注解里面加上method=RequestMethod.GET
1.14 怎样在方法里面得到Request,或者Session
直接在方法的形参中声明request,SpringMvc就自动把request对象传入
1.15 如果想在拦截的方法里面得到从前台传入的参数,怎么得到
直接在形参里面声明这个参数就可以,但必须名字和传过来的参数一样
1.16 如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个对象
直接在方法中声明这个对象,SpringMvc就自动会把属性赋值到这个对象里面
1.17 SpringMvc中函数的返回值是什么
返回值可以有很多类型,有String, ModelAndView。ModelAndView类把视图和数据都合并的一起的,但一般用String比较好
1.18 SpringMvc用什么对象从后台向前台传递数据的
通过ModelMap对象,可以在这个对象里面调用put方法,把对象加到里面,前台就可以通过el表达式拿到
1.19 怎么样把ModelMap里面的数据放入Session里面
可以在类上面加上@SessionAttributes注解,里面包含的字符串就是要放入session里面的key
1.20 SpringMvc里面拦截器是怎么写的
有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器类,接着在接口方法当中,实现处理逻辑;然后在SpringMvc的配置文件中配置拦截器即可:
<!-- 配置SpringMvc的拦截器 -->
<mvc:interceptors>
<!-- 配置一个拦截器的Bean就可以了 默认是对所有请求都拦截 -->
<bean id="myInterceptor" class="com.zwp.action.MyHandlerInterceptor"></bean>
<!-- 只针对部分请求拦截 -->
<mvc:interceptor>
<mvc:mapping path="/modelMap.do" />
<bean class="com.zwp.action.MyHandlerInterceptorAdapter" />
</mvc:interceptor>
</mvc:interceptors>
1.21 注解原理
注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象。通过代理对象调用自定义注解的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池;
Spring
1.22 SpringBean生命周期
Spring帮我们创建了对象,我们称之为Bean,
- 调用构造方法实例化Bean对象
- 设置Bean属性(调用Bean的set方法)
- 如果实现各种Aware接口声明了依赖关系(即Bean实现了各种Aware接口),则会注入Bean对容器基础设施层面的依赖。Aware接口具体包括BeanNameAware、BeanFactoryAware、ApplicationContextAware,分别注入Bean ID、Bean Factory或者ApplicationContext
- 如果实现了BeanPostProcessor,调用BeanPostProcessor的前置初始化方法postProcessBeforeInitialization
- 如果实现了InitialiaingBean接口,则会调用afterPropertiesSet方法
- 调用Bean自身的init方法
- 调用BeanPostProcessor的后置方法postProcessAfterInitialization。
创建完毕,销毁:销毁分两步,先销毁接口里的方法,再销毁自身的方法
- DisposableBean的destory方法和自身的destory方法
SpringBean作用域
我们很少去修改SpringBean作用域,默认作用域是单例的,Spring使用单例的目的,是使用IOC控制反转解决耦合的情况;也可以设置为prototype;
如果使用默认的singleton,结果是true,代表是同一个对象

如果使用prototype

结果是false,代表是两个不同的对象

SpringBean所有作用域
- singleton:Spring默认作用域,每个IOC容器创建唯一的一个Beaan
- prototype:针对每个getBean请求,容器会单独创建一个Bean实例
- request:针对每个HTTP请求都创建单独的Bean实例
- session:比request范围大一些,同一个session范围内使用一个Bean
- GlobalSession:用于PortLet容器中,提供了一个全局的HTTP session;
Spring所有作用域
- singleton:Spring默认作用域,每个IOC容器创建唯一的一个Beaan
- prototype:针对每个getBean请求,容器会单独创建一个Bean实例
- request:针对每个HTTP请求都创建单独的Bean实例
- session:比request范围大一些,同一个session范围内使用一个Bean
- GlobalSession:用于PortLet容器中,提供了一个全局的HTTP session;
Spring五种隔离级别

概念介绍
-
脏读:一个事物读取到另一个事物还没有提交的数据
-
不可重复读:同一个事物里,两次去读取相同的数据,读取到的结果不一样,产生的原因是另一条事物对这个事物进行了修改
-
幻读:同一个事物里,查询到的结果多了或者少了,像产生幻觉一样。比如注册用户时,用户名已经有的话给出提示,用户已存在,不可以注册。当两个线程同时去做注册时(用户名都是张三),在数据库里查的时候都没有,都去做insert,线程1先insert进去了,线程2去insert时,被告知数据库里已经有张三这个用户了,即对于线程2来说,前边查的与后边查的,得到的结果不一样(前边查的没有张三,后边查时又有了),此时对于线程2来说就是幻读;
隔离级别
- ISOLATIO_DEFAULT:其实不是单独的隔离级别,指的是使用数据库默认的隔离级别(mysql是可重复度的级别);
- ISOLATIO_READ_UNCOMMITTED:读未提交,最低级别,允许看到其他事物未提交的事物,会产生脏读、幻读、不可重复读;
- ISOLATIO_READ_COMMITTED:读已提交,只能读到自己已经提交的数据,可以防止脏读,会产生幻读、不可重复读;
- ISOLATIO_REPEATABLE_READ:可重复度,可以防止脏读、不可重复读、产生幻读;
- ISOLATIO_SERIALIZABLE:最高级别,事物处理为串行、阻塞的,能避免所有情况,但是性能下降了;
Spring事物传播机制
事物传播机制:指的是在一个方法里,有多个事物的时候,怎么去处理;Spring的传播机制有以下七种:

- PROPAGATION_REQUIREC:支持当前事物,如果当前没有事物,就新建一个事物,这是最常见的选择
- PROPAGATION_SUPPORTS:支持当前事物,如果当前没有事物,就以非事物方式执行
- PROPAGATION_MANDATORY:支持当前事物,如果当前没有事物,就抛出异常
- PROPAGATION_NESTED:支持当前事物,如果当前事物存在,则执行一个嵌套事物,如果当前没有事物,就新建一个事物(外层事物的回滚会引起内层事物的回滚,反之不成立)
- PROPAGATION_REQUIRES_NEW:支持当前事物,如果当前事物存在,则把当前事物挂起(一旦内层事物提交后,外层事物不能对其进行回滚,两个事物互不影响)
- PROPAGATION_NOT_SUPPORTED:以非事物方式执行操作,如果当前事物存在,就把当前事物挂起
- PROPAGATION_NEVER:以非事物方式执行操作,如果当前事物存在,则抛出异常
Spring设计模式
-
工厂模式:Spring容器就是工厂模式(BeanFactory和ApplicationContext应用了工厂模式)
-
单例和原型模式:在Bean创建的时候,Spring提供了单例(singleton)和原型模式(protoType)
-
代理模式:AOP用到的是代理模式(在原有方法上进行增强,但没有改变原代码)、装饰器模式、适配器模式
-
观察者模式:事件监听器
-
模版模式:类似JdbcTemplate等模版对象(因为里边已经封装好了一些方法)
二、Redis
2.1 QPS: 应用系统每秒钟最大能接受的用户访问量
每秒钟处理完请求的次数,注意这里是处理完,具体是指发出请求到服务器处理完成功返回结果。可以理解在server中有个counter,每处理一个请求加1,1秒后counter=QPS。
2.2 TPS: 每秒钟最大能处理的请求数
每秒钟处理完的事务次数,一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能会对应多个请求,对于衡量单个接口服务的处理能力,用QPS比较合理
2.3 使用Redis的优势与劣势
优势
-
速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
-
支持丰富数据类型,支持string,list,set,sorted set,hash
-
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
-
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
劣势
Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
2.4 Redis为什么是单线程的
多线程处理会涉及到锁,而且多线程处理会涉及到线程切换而消耗CPU。因为CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存或者网络带宽。单线程无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来解决。
2.5 支持多种类型的数据结构
-
string:最基本的数据类型,二进制安全的字符串,最大512M。
-
list:按照添加顺序保持顺序的字符串列表。
-
set:无序的字符串集合,不存在重复的元素。
-
sorted set:已排序的字符串集合。
-
hash:key-value对的一种集合。
每种数据类型的应用场景
- String
最常规的set/get操作,value可以是String也可以是数字。一般做一些复杂的计数功能的缓存。 - hash
value存放的是结构化的对象,可以方便的操作其中的某个字段。比如做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置20分钟为缓存过期时间,能很好的模拟出类似session的效果。 - list
使用List的数据结构,可以做简单的消息队列的功能。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。还可以做简单的生产者和消费者的场景。LIST可以很好的完成排队,先进先出的原则。 - set
因为set堆放的是一堆不重复值的集合,所以可以做全局去重的功能。那问题来了,为什么不用JVM自带的Set进行去重?因为我们的系统一般都是集群部署,使用JVM自带的Set,比较麻烦,难道为了一个模块去做一个全局去重,再起一个公共服务,太麻烦了。
另外,就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。 - sorted set
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
2.6 持久化方式
Redis主要提供了两种持久化机制:RDB和AOF
RDB
默认开启,会按照配置的指定时间将内存中的数据快照到磁盘中,创建一个dump.rdb文件,Redis启动时再恢复到内存中。
Redis会单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程的内存中,然后由子进程写入到临时文件中,持久化的过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,内存释放。
需要注意的是,每次快照持久化都会将主进程的数据库数据复制一遍,导致内存开销加倍,若此时内存不足,则会阻塞服务器运行,直到复制结束释放内存;都会将内存数据完整写入磁盘一次,所以如果数据量大的话,而且写操作频繁,必然会引起大量的磁盘I/O操作,严重影响性能,并且最后一次持久化后的数据可能会丢失;
AOF
以日志的形式记录每个写操作(读操作不记录),只需追加文件但不可以改写文件,Redis启动时会根据日志从头到尾全部执行一遍以完成数据的恢复工作。包括flushDB也会执行。
主要有两种方式触发:有写操作就写、每秒定时写(也会丢数据)。
因为AOF采用追加的方式,所以文件会越来越大,针对这个问题,新增了重写机制,就是当日志文件大到一定程度的时候,会fork出一条新进程来遍历进程内存中的数据,每条记录对应一条set语句,写到临时文件中,然后再替换到旧的日志文件(类似rdb的操作方式)。默认触发是当aof文件大小是上次重写后大小的一倍且文件大于64M时触发。
如何选择持久化
当两种方式同时开启时(默认使用RDB),Redis会优先选择AOF还原数据。一般情况下,只要使用默认开启的RDB即可,因为相对于AOF,RDB便于进行数据库备份,并且恢复数据集的速度也要快很多。
开启持久化缓存机制,对性能会有一定的影响,特别是当设置的内存满了的时候,更是下降到几百reqs/s。所以如果只是用来做缓存的话,可以关掉持久化;
2.7 什么是缓存穿透?如何避免?
缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如Oracle、Mysql等)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
如何避免
- 对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
- 对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
2.8 什么是缓存雪崩?何如避免?
缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
何如避免
-
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
-
做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
-
不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
2.9 Redis集群方案应该怎么做?都有哪些方案?
- twemproxy,它类似于一个代理方式,使用方法和普通redis无任何区别,设置好它下属的多个redis实例后,使用时在本需要连接redis的地方改为连接twemproxy,它会以一个代理的身份接收请求并使用一致性hash算法,将请求转接到具体redis,将结果再返回twemproxy。使用方式简便(相对redis只需修改连接端口),是对旧项目扩展的首选。 问题:twemproxy自身单端口实例的压力,使用一致性hash后,对redis节点数量改变时候的计算值的改变,数据无法自动移动到新的节点。
- codis,目前用的最多的集群方案,基本和twemproxy一致的效果,但它支持在节点数量改变情况下,旧节点数据可恢复到新hash节点。
- redis cluster3.0自带的集群,特点在于他的分布式算法不是一致性hash,而是hash槽的概念,以及自身支持节点设置从节点。具体看官方文档介绍。
- 在业务代码层实现,起几个毫无关联的redis实例,在代码层,对key 进行hash计算,然后去对应的redis实例操作数据。 这种方式对hash层代码要求比较高,考虑部分包括,节点失效后的替代算法方案,数据震荡后的自动脚本恢复,实例的监控,等等。
2.10 Redis集群方案什么情况下会导致整个集群不可用?
有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用。
2.11 MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
2.12 Redis有哪几种数据淘汰策略?
- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
2.13 Redis有哪些适合的场景?
- 会话缓存(Session Cache):最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
- 全页缓存(FPC):除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
- 队列:Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
- 排行榜/计数器:Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”;当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:ZRANGE user_scores 0 10 WITHSCORESAgora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的。
- 发布/订阅:发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!
2.14 Redis哈希槽的概念
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
2.15 Redis集群之间是如何复制的?
异步复制
2.16 Redis集群会有写操作丢失吗?为什么?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
2.17 Redis集群最大节点个数是多少?
16384个。
2.18 Redis集群如何选择数据库?
Redis集群目前无法做数据库选择,默认在0数据库。
2.19 怎么测试Redis的连通性?
ping
2.20 Redis中的管道有什么用?
一次请求/响应服务器能实现处理新的请求,即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多POP3协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
2.21 怎么理解Redis事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
2.22 Redis事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH ##28、Redis key的过期时间和永久有效分别怎么设置? EXPIRE和PERSIST命令。
2.23 Redis如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面.
2.24 Redis回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。一个新的命令被执行,等等。所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
2.25 Redis回收使用的是什么算法?
LRU算法
2.26 Redis如何做大量数据插入?
Redis2.6开始redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
2.27 为什么要做Redis分区?
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
2.28 你知道有哪些Redis分区实现方案?
客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
2.29 Redis分区有什么缺点?
涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。同时操作多个key,则不能使用Redis事务.分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set).当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
2.30 Redis持久化数据和缓存怎么做扩容?
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样。
2.31 分布式Redis是前期做还是后期规模上来了再做好?为什么?
既然Redis是如此的轻量(单实例只使用1M内存),为防止以后的扩容,最好的办法就是一开始就启动较多实例。即便你只有一台服务器,你也可以一开始就让Redis以分布式的方式运行,使用分区,在同一台服务器上启动多个实例。一开始就多设置几个Redis实例,例如32或者64个实例,对大多数用户来说这操作起来可能比较麻烦,但是从长久来看做这点牺牲是值得的。这样的话,当你的数据不断增长,需要更多的Redis服务器时,你需要做的就是仅仅将Redis实例从一台服务迁移到另外一台服务器而已(而不用考虑重新分区的问题)。一旦你添加了另一台服务器,你需要将你一半的Redis实例从第一台机器迁移到第二台机器。
2.32 Twemproxy是什么?
Twemproxy是Twitter维护的(缓存)代理系统,代理Memcached的ASCII协议和Redis协议。它是单线程程序,使用c语言编写,运行起来非常快。它是采用Apache 2.0 license的开源软件。 Twemproxy支持自动分区,如果其代理的其中一个Redis节点不可用时,会自动将该节点排除(这将改变原来的keys-instances的映射关系,所以你应该仅在把Redis当缓存时使用Twemproxy)。 Twemproxy本身不存在单点问题,因为你可以启动多个Twemproxy实例,然后让你的客户端去连接任意一个Twemproxy实例。 Twemproxy是Redis客户端和服务器端的一个中间层,由它来处理分区功能应该不算复杂,并且应该算比较可靠的。
2.33 支持一致性哈希的客户端有哪些?
Redis-rb、Predis等。
2.34 Redis与其他key-value存储有什么不同?
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,应为数据量不能大于硬件内存。在内存数据库方面的另一个优点是, 相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。 同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
2.35 Redis的内存占用情况怎么样?
给你举个例子: 100万个键值对(键是0到999999值是字符串“hello world”)在我的32位的Mac笔记本上 用了100MB。同样的数据放到一个key里只需要16MB, 这是因为键值有一个很大的开销。 在Memcached上执行也是类似的结果,但是相对Redis的开销要小一点点,因为Redis会记录类型信息引用计数等等。当然,大键值对时两者的比例要好很多。64位的系统比32位的需要更多的内存开销,尤其是键值对都较小时,这是因为64位的系统里指针占用了8个字节。 但是,当然,64位系统支持更大的内存,所以为了运行大型的Redis服务器或多或少的需要使用64位的系统。
2.36 都有哪些办法可以降低Redis的内存使用情况呢?
如果你使用的是32位的Redis实例,可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。
2.37 查看Redis使用情况及状态信息用什么命令?
info
2.38 Redis的内存用完了会发生什么?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以将Redis当缓存来使用配置淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
2.39 Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
2.40 一个Redis实例最多能存放多少的keys?
List、Set、Sorted Set他们最多能存放多少元素?理论上Redis可以处理多达232的keys,并且在实际中进行了测试,每个实例至少存放了2亿5千万的keys。我们正在测试一些较大的值。任何list、set、和sorted set都可以放232个元素。换句话说,Redis的存储极限是系统中的可用内存值。
2.41 Redis常见性能问题和解决方案?
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
2.42 Redis提供了哪几种持久化方式?
RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式.你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整.最重要的事情是了解RDB和AOF持久化方式的不同,让我们以RDB持久化方式开始。
2.43 如何选择合适的持久化方式?
一般来说, 如果想达到足以媲美PostgreSQL的数据安全性, 你应该同时使用两种持久化功能。如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失,那么你可以只使用RDB持久化。有很多用户都只使用AOF持久化,但并不推荐这种方式:因为定时生成RDB快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比AOF恢复的速度要快,除此之外, 使用RDB还可以避免之前提到的AOF程序的bug。
2.44 修改配置不重启Redis会实时生效吗?
针对运行实例,有许多配置选项可以通过 CONFIG SET 命令进行修改,而无需执行任何形式的重启。 从 Redis 2.2 开始,可以从 AOF 切换到 RDB 的快照持久性或其他方式而不需要重启 Redis。检索 ‘CONFIG GET *’ 命令获取更多信息。但偶尔重新启动是必须的,如为升级 Redis 程序到新的版本,或者当你需要修改某些目前 CONFIG 命令还不支持的配置参数的时候。
三、Shiro
3.1 什么是shiro
Shiro是一个强大易用的java安全框架,提供了认证、授权、加密、会话管理、与web集成、缓存等功能,对于任何一个应用程序,都可以提供全面的安全服务,相比其他安全框架,shiro要简单的多。
3.2 Shiro的核心概念Subject、SecurityManager、Realm
Subject
主体,代表了当前“用户”,这个用户不一定是一个具体的人,与当前应用交互的任何东西都是Subject,如爬虫、机器人等,即Subject是一个抽象概念;所有Subject都绑定到SecurityManager,与Subject的所有交互都会委托给SecurityManager;可以把Subject认为是一个门面;SecurityManager才是实际的执行者。
SecurityManager
安全管理器,即所有与安全有关的操作都会与SecurityManager交互,且它管理着所有Subject;可以看出它是shiro的核心, SecurityManager相当于SpringMVC中的DispatcherServlet前端控制器。
Realm
域,shiro从Realm获取安全数据(如用户、角色、权限),Realm是与持久层交互的桥梁,就是说SecurityManager要验证用户身份,那么它需要从Realm获取相应的用户进行比较以确定用户身份是否合法;也需要从Realm得到用户相应的角色/权限进行验证用户是否能进行操作;可以把Realm看成DataSource,即安全数据源。
3.3 Authentication 身份验证
principals
身份,即主体的标识属性,可以是任何东西,如用手机号、户名、邮箱等,唯一即可。
credentials
证明/凭证,即只有主体知道的安全值,如密码/数字证书等。
身份认证流程
- 首先调用Subject.login(token)进行登录,其会自动委托给SecurityManager,调用之前必须通过SecurityUtils.setSecurityManager()设置;
- SecurityManager负责真正的身份验证逻辑;它会委托给Authenticator进行身份验证;
- Authenticator才是真正的身份验证者,是Shiro API中核心的身份认证入口点,此处可以自定义插入自己的实现;
- Authenticator可能会委托给相应的AuthenticationStrategy进行多Realm身份验证,默认ModularRealmAuthenticator会调用AuthenticationStrategy进行多Realm身份验证;
- Authenticator会把相应的token传入Realm,从Realm获取身份验证信息,如果没有返回/抛出异常表示身份验证失败了。此处可以配置多个Realm,将按照相应的顺序及策略进行访问。
Authenticator及AuthenticationStrategy
- Authenticator的职责是验证用户账号,是Shiro API中身份验证核心的入口点。
- AuthenticationStrategy 认证策略 ModularRealmAuthenticator默认使用AtLeastOneSuccessfulStrategy策略
- FirstSuccessfulStrategy:只要有一个Realm验证成功即可,只返回第一个Realm身份验证成功的认证信息,其他的忽略;
- AtLeastOneSuccessfulStrategy:只要有一个Realm验证成功即可,和FirstSuccessfulStrategy不同,返回所有Realm身份验证成功的认证信息;
- AllSuccessfulStrategy:所有Realm验证成功才算成功,且返回所有Realm身份验证成功的认证信息,如果有一个失败就失败了。
自定义实现认证时一般继承AbstractAuthenticationStrategy即可
3.4 Authorization 授权
授权,也叫访问控制,即在应用中控制谁能访问哪些资源(如访问页面/编辑数据/页面操作等)。在授权中需了解的几个关键对象:主体(Subject)、资源(Resource)、权限(Permission)、角(Role)
授权方式:
- 编程式:通过写if/else授权代码完成
Subject subject = SecurityUtils.getSubject();
If(subject.hasRole(“admin”){
// 有权限
}else{
// 无权限
} - 注解
@RequiresRoles(“admin”)
public void helloWord(){
// 有权限
} - Jsp/gsp标签
<shiro:hasRole name = “admin”>
<!—有权限
</shiro:hasRole>
基于资源的访问控制
1. 隐式角色:硬编码的方式(if/else);粗粒度造成的问题:如果有一天不需要了那么就需要修改相应代码把所有相关的地方进行删除; - 显示角色:规则:资源标识符:操作(user:create,user:update)这种方式叫资源级别的粒度;好处:如果需要修改都是一个资源级别的修改,不会对其他模块代码产生影响,粒度小;但实现起来可能稍微复杂点,需要维护“用户—角色,角色—权限(资源:操作)”之间的关系
Permission
字符串通配符权限
规则:资源标识符 : 操作 : 对象实例ID
“:”表示资源/操作/实例的分割
“,”表示操作的分割
“*”表示任意资源/操作/实例 - 单个资源多个权限
Role=system:user:update,system:user:delete
等价于role=system:user:update,delete,但是反过来是规则不成立
代码判断
subject().checkPermissions(“system:user:update,delete”) - 单个资源全部权限:role=sys:user:*/sys:user
- 所有资源全部权限:role=*:view;subject.checkPermissions(“user:view”);
- 实例级别的权限
单实多限:role=”user:update,delete:1”;
subject().checkPermissions(”user:update,delete:1”);
all实单限:role=”user:auth:”;
subject().checkPermissions(“user:auth:1”, “user:auth:2”);
all实all限:role=”user:?”;
subject().checkPermissions(“user:view:1”, “user:auth:2”);
授权流程:
- 首先调用Subject.isPermitted
hasRole接口,其会委托给SecurityManager,而SecurityManager接着会委托给Authorizer; - Authorizer是真正的授权者,如果我们调用如isPermitted(“user:view”), 其首先会通过PermissionResolver把字符串转换成相应的Permission实例;在进行授权之前,其会调用相应的Realm获取Subject相应的角色/权限用于匹配传入的角色/权限;
- Authorizer会判断Realm的角色/权限是否和传入的匹配,如果有多个Realm,会委托给 ModularRealmAuthorizer进行循环判断,如果匹配如isPermitted
hasRole会返回true, 否则返回false表示授权失败。
3.5 加密
编码/解码
Shiro提供了base64和16进制字符串编码/解码的API支持,方便一些编码解码操作
//编码
Base64.encodeToString(str.getBytes())
//解码
Base64.decodeToString(base64Encoded)
散列算法
常见散列算法如MD5,SHA等
- 首先创建一个DfaultHashService,默认使用SHA-512算法;
- 可以通过hashAlgorithmName属性修改算法;
- 可以通过privateSalt设置一个私盐,其在散列时自动与用户传入的公盐混合产生一个新盐;
- 可以通过generatePublicSalt属性在用户没有传入公盐的情况下设置是否生成公盐;
- 可以设置randomNumberGenerator用于生成公盐;
- 可以设置hashIterations属性来修改默认加密迭代次数;
- 需要构建一个HashRequest,传入算法、数据、公盐、迭代次数。
生成随机数
SecureRandomNumberGenerator randomNumberGenerator = new SecureRandomNumberGenerator();
randomNumberGenerator.setSeed(“159”.getBytes());
String hex = randomNumberGenerator.nextBytes().toHex();
加密/解密
提供对称式加密/解密算法的支持,如AES、Blowfish等
PasswordService/CredentialsMatcher用于提供加密密码及验证密码服务
Shiro默认提供了PasswordService实现DefaultPasswordService;CredentialsMatcher实现PasswordMatcher及HashedCredentialsMatcher(更强大)
HashedCredentialsMatcher实现密码验证服务
Shiro提供了CredentialsMatcher的散列实现HashedCredentialsMatcher,和PasswordMatcher不同的是,它只是用于密码验证,且可以提供自己的盐,而不是随机生成盐,且生成密码散列值的算法需要自己写,因为能提供自己的盐;
3.5 Realm 域
定义Realm(自定义Realm继承AuthorizingRealm即可)
- UserRealm父类AuthorizingRealm将获取Subject相关信息分成两步:获取身份验证信息(doGetAuthenticationInfo)及授权信息(doGetAuthorizationInfo)
- doGetAuthenticationInfo获取身份验证相关信息:首先根据传入的用户名获取User信息;如果user为空,那么抛出没找到账号异常UnknownAccountExecption;如果user找到但却被锁定了抛出锁定异常LockedAccountException;最后生成AuthenticationInfo信息,交给间接父类AuthenticatingRealm使用CredentialsMatcher进行判断密码是否匹配,如果不匹配将抛出密码错误异常信息IncorrectCredentialsException;如果密码重试次数太多将抛出超出重试次数异常ExcessiveAttemptsException;在组装SimpleAuthenticationInfo信息时,需要传入:身份信息(用户名)、凭据(密文密码)、盐(username+salt),CredentialsMatcher使用盐加密传入的明文密码和此处的密文密码进行匹配。
- doGetAuthorizationInfo获取授权信息:PrincipalCollection是一个身份集合,因为只用到了一个Realm,所以直接调用getPrimaryPrincipal得到之前传入的用户名即可;然后根据用户名调用UserService接口获取角色及权限信息。
AuthenticationInfo的两个作用
- 如果Realm是AuthenticatingRealm子类,则提供给AuthenticatingRealm内部使用的CredentialsMatcher进行凭据验证;(如果没有继承它需要在自己的Realm中实现验证);
- 提供给SecurityManager来创建Subject(提供身份信息);
3.6 拦截器
基于表单登录拦截器
onPreHandle主要流程:
- 首先判断是否已经登录过了,如果已经登录过了继续拦截器链即可;
- 如果没有登录,看看是否是登录请求,如果是get方法的登录页面请求,则继续拦截器链(到请求页面),否则如果是get方法的其他页面请求则保存当前请求并重定向到登录页面;
- 如果是post方法的登录页面表单提交请求,则收集用户名/密码登录即可,如果失败了保存错误消息到“shiroLoginFailure”并返回到登录页面;
- 如果登录成功了,且之前有保存的请求,则重定向到之前的这个请求,否则到默认的成功页面。
任意角色授权拦截器
流程:
- 首先判断用户有没有任意角色,如果没有返回false,将到onAccessDenied进行处理;
- 如果用户没有角色,接着判断用户有没有登录,如果没有登录先重定向到登录;
- 如果用户没有角色且设置了未授权页面(unauthorizedUrl),那么重定向到未授权页面;否则直接返回401未授权错误码。
默认拦截器
身份验证相关的
authc 基于表单的拦截器,即验证成功之后才能访问 /=authc
authcBasic Basic HTTP身份验证拦截器,主要属性:applicationName
logout 退出 /logout=logout
user 用户拦截器 /=user
anon 匿名拦截器,一般用于静态资源过滤 /static/=anon
授权相关的
roles 角色授权拦截器,主要属性:loginUrl,unauthorizedUrl /admin/=roles[admin]
perms 权限授权拦截器 /user/**=perms[“user:create”]
port 端口拦截器,主要属性: port(80) /test=port[80]
rest rest风格拦截器 /users=rest[user],会自动拼接出“user:read,user:create,user:update,user:delete”
ssl ssl拦截器,只有请求协议是https才能通过
3.7 Session Manager 会话管理
Session
所谓session,即用户访问应用时保持的连接关系,在多次交互中应用能够识别出当前访问的用户是谁,且可以在多次交互中保存一些数据。
Subject subject = SecurityUtils.getSubject();
Session session = subject.getSession();
session.getId(); // 获取当前session的唯一标识
session.getHost(); // 获取当前Subject的主机地址,该地址是通过HostAuthenticationToken.getHost()提供的
session.getTimeOut(); // 获取超时时间
session.setTimeOut(); // 设置超时时间(不设置默认是全局过期时间)
session.touch(); // 更新最后访问时间
session.stop(); // 销毁session,当Subject.logout()时会自动调用stop方法来销毁会话。如果在web中,调用javax.servlet.http.HttpSession.invalidate()也会自动调用shiro session.top方法进行销毁shiro的会话
session.setAttribute(“key”,”123”); // 设置session属性
session.getAttribute(“key”); // 获取session属性
session.removeAttribute(“key”); // 删除属性
注:Shiro提供的会话可以用于javaSE/javaEE环境,不依赖于任何底层容器,可以独立使用,是完整的会话模块。
Session manager 会话管理器
会话管理器管理着应用中所有Subject的会话的创建、维护、删除、失效、验证等工作。是Shiro的核心组件,顶层组件SecurityManager直接继承了SessionManager,且提供了SessionSecurityManager实现直接把会话管理委托给相应的SessionManager、DefaultSecurityManager及DefaultWebSecurityManager 默认SecurityManager都继承了SessionSecurityManager。
Shiro提供了三个默认实现
- DefaultSessionManager:DefaultSecurityManager使用的默认实现,用于JavaSE环境;
- ServletContainerSessionManager: DefaultWebSecurityManager使用的默认实现,用于Web环境,其直接使用Servlet容器的会话;
- DefaultWebSessionManager:用于Web环境的实现,可以替代ServletContainerSessionManager,自己维护着会话,直接废弃了Servlet容器的会话管理。
3.8 Shiro注解
- @RequiresAuthentication : 表示当前Subject已经通过login进行了身份验证;即 Subject.isAuthenticated() 返回 true
- @RequiresUser : 表示当前Subject 已经身份验证或者通过
记住我登录的 - @RequiresGuest : 表示当前Subject没有身份验证或通过
记住我登陆过,即是游客身份 - @RequiresRoles(value = { “admin”, “user” }, logical = Logical.AND) : 表示当前 Subject 需要角色 admin和user
- @RequiresPermissions(value = { “user:a”, “user:b” }, logical = Logical.OR) : 表示当前 Subject 需要权限 user:a 或 user:b
3.9 shiro的优点
- 简单的身份验证,支持多种数据源
- 对角色的简单授权,支持细粒度的授权(方法)
- 支持一级缓存,以提升应用程序的性能
- 内置基于POJO的企业会话管理,适用于web及非web环境
- 非常简单的API加密
- 不跟任何框架绑定,可以独立运行
四 集合
4.1 ArrayList、LinkedList、Vector
都继承Collection接口
ArrayList
有序可重复,底层是数组结构,查询快,增删慢
LinkedList
有序可重复,底层是链表结构,查询慢,增删快
Vector
Vector使用了synchronized方法-线程安全,性能上比ArrayList差一点
4.2 Set
和List一样,继承Collection接口,不同的是Set集合是不可重复的(不一定是无序的),并且最多只能允许一个null值。Set常见的实现类有:HashSet、TreeSet和LinkedHashSet。
HashSet
HashSet是一个没有重复元素的集合。它是由HashMap实现的,不能保证元素的顺序,重要的是HashSet允许使用null元素。
HashSet是非同步的。如果多个线程同时访问一个hashset,而其中至少一个线程修改了该hashset,那么它必须保持外部同步。
TreeSet
是一个有序的集合,是一个set集合。继承abstractset,实现了navigableset,cloneable,serializable接口。
LinkedHashSet
是一个有序集合
4.3 Map
HashMap、HashTable都继承Map接口
HashMap
线程不安全,使用HashMap要注意避免集合的扩容,它会很耗性能,根据元素的数量给它一个初始大小的值(HashMap是数组和链表组成的,默认大小为16,当hashmap中的元素个数超过数组大小*loadFactor(默认值为0.75)时就会把数组的大小扩展为原来的两倍大小,然后重新计算每个元素在数组中的位置)。HashMap的键值都可以为NULL,HashTable不行。
HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,采用哈希表来存储的;
HashTable
线程安全,key、value不可以为null;
LinkedHashMap
按照添加顺序存储元素(按自然顺序存储元素则使用TreeMap,按照自定义顺序存储元素也使用TreeMap(Comparetor c))
有没有有顺序的 Map 实现类? 如果有, 他们是怎么保证有序的?
TreeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。
五 Oracle数据库
5.1 数据库的三大范式
-
第一范式:原子件,要求每一列的值不能再拆分了。
-
第二范式: 一张表只描述一个实体(若列中有冗余数据,则不满足)
-
第三范式: 所有列与主键值直接相关。
5.2 事务的特性(ACID)
-
原子性(Atomic): 事务中的各项操作,要么全做要么全不做,任何一项操作的失败都会导致整个事务的失败。
-
一致性(Consistent): 事务前后数据的完整性必须保持一致。
-
隔离性(Isolated):多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
-
持久性(Durable):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
5.3 oracle中 dml、ddl、dcl
Dml 数据操做语言,如select、update、delete,insert
Ddl 数据定义语言,如create table 、drop table、Truncate 等等
Dcl 数据控制语言, 如 commit、 rollback、grant、 invoke等
5.4 索引
建索引的原则
- 索引字段建议建立NOT NULL约束
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段且过滤性很强的,特别是大表的字段,应该建立索引;
- 可选择性高的关键字 ,应该建立索引;
- 不要将那些频繁修改的列作为索引列;
索引缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度
- 索引创建在表上,不能创建在视图上
5.5 oracle中的经常使用到得函数
Length 长度、 lower 小写、upper 大写, to_date 转化日期, to_char转化字符
Ltrim 去左边空格、 rtrim去右边空格,substr取字串,add_month增加或者减掉月份、to_number转变为数字
5.6 Oracle是怎样分页的
Oracle中使用rownum来进行分页, 这个是效率最好的分页方法,hibernate也是使用rownum来进行oralce分页的
select * from
( select rownum r,a from tabName where rownum <= 20 )
where r > 10
5.7 truncate和delete命令的区别
- Truncate 和delete都可以将数据实体删掉,truncate 的操作并不记录到 rollback日志,所以操作速度较快,但同时这个数据不能恢复
- Delete操作不腾出表空间的空间
- Truncate 不能对视图等进行删除
- Truncate是数据定义语言(DDL),而delete是数据操纵语言(DML)
5.8 什么是死锁,如何解决Oracle中的死锁
死锁
就是存在加了锁而没有解锁,可能是使用锁没有提交或者没有回滚事务;如果是表级锁则不能操作表,客户端处于等在状态,如果是行级锁则不能操作锁定行;
解决死锁
- 查找出被锁的表
select b.owner,b.object_name,a.session_id,a.locked_mode
from v$locked_object a,dba_objects b
where b.object_id = a.object_id;
select b.username,b.sid,b.serial#,logon_time
from v$locked_object a,v$session b
where a.session_id = b.sid order by b.logon_time;
- 杀进程中的会话
alter system kill session "sid,serial#";
5.9 四种隔离级别
-
读未提交(Read uncommitted):
这种事务隔离级别下,select语句不加锁。
此时,可能读取到不一致的数据,即“读脏 ”。这是并发最高,一致性最差的隔离级别。 -
读已提交(Read committed):
可避免 脏读 的发生。
在互联网大数据量,高并发量的场景下,几乎 不会使用 上述两种隔离级别。 -
可重复读(Repeatable read):
MySql默认隔离级别。
可避免脏读 、不可避免重复读的发生。 -
串行化(Serializable ):
可避免 脏读、不可重复读、幻读 的发生。
以上四种隔离级别最高的是 Serializable 级别,最低的是 Read uncommitted 级别,当然级别越高,执行效率就越低。像 Serializable 这样的级别,就是以 锁表 的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读) 。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读) ;而在 Oracle数据库 中,只支持Serializable (串行化) 级别和 Read committed (读已提交) 这两种级别,其中默认的为 Read committed(读已提交) 级别。
六 SpringBoot
6.1 什么是 SpringBoot
SpringBoot 是 Spring 开源组织下的子项目,是 Spring 组件一站式解决方案,主要是简化了使用 Spring 的难度,简省了繁重的配置,提供了各种启动器,开发者能快速上手。Spring Boot 与传统项目最大的区别是,传统项目都是打成 WAR 包部署到服务器上面,需要额外的 Servlet 容器, 而 Spring Boot 则可以直接打成 jar包,并内置集成了 Servlet 容器,通过命令 java -jar xx.jar 则可以直接运行,不需要独立的 Servlet 容器。
6.2 SpringBoot优点
一、独立运行
Spring Boot而且内嵌了各种servlet容器,Tomcat、Jetty等,现在不再需要打成war包部署到容器中,Spring Boot只要打成一个可执行的jar包就能独立运行,所有的依赖包都在一个jar包内。
二、简化配置
spring-boot-starter-web启动器自动依赖其他组件,简少了maven的配置。相对于SpringMVC,SpringBoot无需XML配置文件就能完成所有配置工作
6.3 SpringBoot 的核心配置文件有哪几个?它们的区别是什么?
Spring Boot 中有以下两种配置文件
- bootstrap (.yml 或者 .properties)
- application (.yml 或者 .properties)
bootstrap与application 的区别
Spring Cloud 构建于 Spring Boot 之上,在 Spring Boot 中有两种上下文,一种是 bootstrap,,另外一种是 application,,bootstrap 是应用程序的父上下文,也就是说 bootstrap 加载优先于 applicaton。bootstrap 主要用于从额外的资源来加载配置信息,还可以在本地外部配置文件中解密属性。这两个上下文共用一个环境,它是任何Spring应用程序的外部属性的来源。bootstrap 里面的属性会优先加载,它们默认也不能被本地相同配置覆盖。
所以,对比 application 配置文件,bootstrap 配置文件具有以下几个特性:
-
boostrap 由父 ApplicationContext 加载,比 applicaton 优先加载
-
boostrap 里面的属性不能被覆盖
bootstrap与application 的应用场景
application 配置文件这个容易理解,主要用于 Spring Boot 项目的自动化配置。
bootstrap 配置文件有以下几个应用场景:
- 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性
- 一些加密/解密的场景。
6.4 Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 SpringBoot 的核心注解,其主要组合包含以下 3 个注解:
-
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
-
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
-
@ComponentScan:Spring组件扫描。
6.5 开启 Spring Boot 特性有哪几种方式?
两种方式
方式一
继承spring-boot-starter-parent项目
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.6.RELEASE</version>
</parent>
方式二
导入spring-boot-dependencies项目依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependencies>
</dependencyManagement>
6.6 如何在 Spring Boot 启动的时候运行一些特定的代码?
如果你想在Spring Boot启动的时候运行一些特定的代码,你可以实现接口ApplicationRunner或者CommandLineRunner,这两个接口实现方式一样,它们都只提供了一个run方法。
使用方式:
package com.qf.service.impl;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
/**
* @Author: sgw
* @Date 2020/3/8 16:12
* @Description: TODO
**/
@Component
public class MyBean implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("启动项目的时候执行这里的代码");
}
}
启动顺序
如果启动的时候有多个ApplicationRunner和CommandLineRunner,想控制它们的启动顺序,可以实现 org.springframework.core.Ordered接口或者使用 org.springframework.core.annotation.Order注解。
6.7 读取配置文件
读取application文件
在application.yml或者properties文件中添加:
info.address=China
方式一、在程序里的属性上加注解读取
@Value("${info.address}")
private String addr;
方式二、在类上加注解,添加前缀后,将属性名称对应上即可
@Component
@ConfigurationProperties(prefix="info")
public class MyTest{
private String addr;
//get/set方法......
}
读取指定文件
资源目录下建立config/db-config.properties:
db.username=root
db.password=123456
方式一、@PropertySource+@Value注解读取方式:
package com.qf.service.impl;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.PropertySource;
import org.springframework.stereotype.Component;
/**
* @Author: sgw
* @Date 2020/3/8 16:12
* @Description: TODO
**/
@Component
@PropertySource(value = {"config/db-config.properties"})
public class MyBean {
@Value("${db.username}")
private String userName;
@Value("${db.password}")
private String passWord;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassWord() {
return passWord;
}
public void setPassWord(String passWord) {
this.passWord = passWord;
}
}
注意:@PropertySource不支持yml文件读取。
方式二、@PropertySource+@ConfigurationProperties注解读取方式:

6.8 SpringBoot 支持哪些日志框架?推荐和默认的日志框架是哪个?
Spring Boot支持Java Util Logging,Log4j2,Lockback作为日志框架,如果你使用starters启动器,Spring Boot将使用Logback作为默认日志框架。无论使用哪种日志框架,Spring Boot都支持配置将日志输出到控制台或者文件中。
spring-boot-starter启动器包含spring-boot-starter-logging启动器并集成了slf4j日志抽象及Logback日志框架。
自定义日志文件
根据不同的日志框架,默认加载的日志配置文件的文件名,放在资源根目录下,其他的目录及文件名不能被加载

既然默认自带了Logback框架,Logback也是最优秀的日志框架,往资源目录下创建一个logback-spring.xml即可。
强烈推荐使用logback-spring.xml作为文件名,因为logback.xml加载太早。
6.9 SpringBoot实现热部署
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
在配置文件里配置热部署

IDEA需要设置:

ctrl+Alt+shift+/


七 java基础
7.1 String, Stringbuffer, StringBuilder 的区别
StringBuffer:线程安全,效率低;
StringBuilder:线程不安全,效率高;
字符串比较
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x==y); // true,引用相同
System.out.println(x==z); // false,==:string比较引用,开辟了新的堆内存空间,所以false
System.out.println(x.equals(y)); // true,equals:string:比较值,相同
System.out.println(x.equals(z)); // true,equals:string比较值,相同
字符串反转
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("abcdefg");
System.out.println(stringBuffer.reverse()); // gfedcba
字符串常用方法
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
7.2、类加载顺序
- 父类静态代变量
- 父类静态代码块
- 子类静态变量
- 子类静态代码块
- 父类非静态变量(父类实例成员变量)
- 父类构造函数
- 子类非静态变量(子类实例成员变量)
- 子类构造函数
7.3 IO流
IO流种类
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
Files的常用方法都有哪些
Files.exists():检测文件路径是否存在。
Files.createFile():创建文件。
Files.createDirectory():创建文件夹。
Files.delete():删除一个文件或目录。
Files.copy():复制文件。
Files.move():移动文件。
Files.size():查看文件个数。
Files.read():读取文件。
Files.write():写入文件。
7.4 get与post区别
- GET把参数包含在URL中,POST通过request body传递参数
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST么有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- 传文件、form表单等必须是post
7.5 异常
1、Exception和Error的区别
Exception和Error都继承自Throwable,在Java中只有Throwable类型的实例才可以被抛出或捕获。
Error指正常情况下不太可能出现的情况,绝大部分的Error或导致程序崩溃,处于非正常的不可恢复的状态,如OutOfMemoryError、StackOverflowError。是程序中不应该试图捕获的严重问题。
Exception是程序正常运行中可以预料的意外情况,可以捕获并处理。
2.运行时异常和一般异常的区别
受检查异常(一般异常):在编译时被强制检查的异常。在方法的声明中声明的异常。
(举例:ClassNotFoundException、IOException)
不受检查异常(运行时异常,都继承自RuntimeException):不受检查异常通常是在编码中可以避免的逻辑错误,根据需求来判断如何处理,不需要再编译期强制要求。
3.写出几种常见的运行时异常(考察编程经验)
运行时异常RuntimeException是所有不受检查异常的基类。
NullPointerException、ClassCastException、NumberFormatException、IndexOutOfBoundsException。
7.6 servlet生命周期
自定义servlet,继承HttpServlet即可,重写init、doGet、doPost、destory方法。servlet是单例的,也就是说在整个容器里只有一个servlet对象;
在web.xml里将servlet与请求地址对应起来:

自定义Servlet:
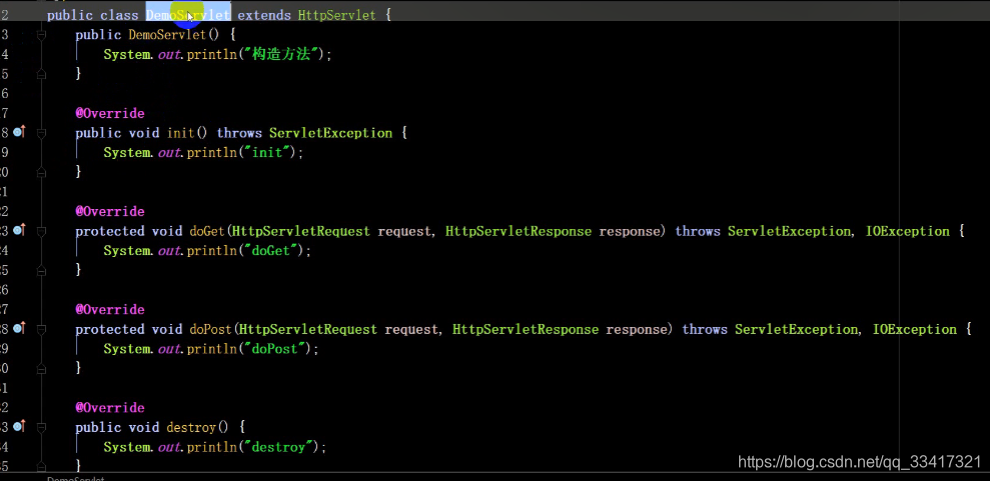
servlet生命周期
- Web容器加载Servlet类并实例化(默认延迟,只加载一次)
- 运行init方法进行初始化(只加载一次)
- 用户请求该servlet,请求到达服务器时,运行其service方法(每请求一次就运行一次,service是父类里的方法,不需要我们自己写)
- service运行与请求对应的doGet/doPost/delete/put方法(每请求一次就运行一次)
- 销毁实例时调用destory方法(只执行一次)
上边的步骤:1-2是初始化阶段,3-4是使用阶段,5是销毁阶段,其中第一步延迟加载,指的是在第一次访问的时候才加载,可以在web.xml里配置为启动容器时就加载,如下

7.7 转发(forward)与重定向(redirect)
- 转发是容器内部控制的跳转,服务器直接访问目标地址,把目标地址响应的数据读取出来,直接发送给浏览器,浏览器是不知道请求从哪里来的,浏览器地址不变
- 重定向是服务器接收请求后,返回一个状态码给浏览器,浏览器去请求新的地址,地址栏会变化
- 转发效率高,尽量使用转发,但是转发不能跳转到其他服务器上,重定向可以跳转到其他服务器;
7.8 数据库连接池工作机制
连接池的作用
-
打开关闭数据库连接非常耗时,频繁开关连接的话就会消耗系统资源,连接池可以控制并发数量
-
可以控制并发数量(比如应用在队列里排队,拿到数据库连接后才可以使用)
连接池工作机制
-
服务器在启动的时候会建立一定数量的连接池,并一直维持不少于此数目的连接池;
-
客户端程序连接时,池驱动程序会返回一个为使用的池连接并将其标记为忙;
-
如果当前没有空闲连接,则池驱动程序会新建一定数量的连接,新建连接具体的数量由配置决定,但是不会超过最大连接数;
-
当使用的池连接调用完之后,池驱动程序就会将此链接标记为空闲,其他调用者就可以使用这个连接了;
7.9 TCP三次握手
先介绍几个简单概念
主机A向主机B发送数据的同时,主机A也可以接收主机B发过来的数据;
在TCP报文包里,有六个标志位 ,这里了介绍其中的两个:SYN包与ACK包;
SYN包:请求建立连接的数据包,SYN=1,则表示要建立连接;
ACK包:回应数据包(用来做回应的),表示接收到了对方的某个数据包,仅当ACK=1时,确认号字段才有效;
seq序列号:用来标记数据包的顺序;
ack确认号:表示序号为确认号减去1的数据包及其以前的所有数据包已经正确接收,也就是说他相当于下一个准备接收的字节的序号 (如果ack确认号是101,则表示前100个都已经收到了);
当我们发一个SYN=1的包时,会得到一个ACK=1的包;
三次握手
第一次握手:建立连接时,客户端发送数据包,标志位SYN=1,随机seq=x到服务器(x代表随机生成的数)
第二次握手:服务器收到SYN=1的包,知道客户端要建立连接,返回SYN=1和ACK=1,ack=x+1,和随机seq=y (y代表随机生成的数)
第三次握手:客户端厚道服务器的SYN+ACK包,向服务器发送确认包ACK=1,ack=y+1
7.10 session与cookie
- session存在服务器里,客户端不知道其中的信息;cookie存在客户端,服务器能够知道其中的信息
- session中保存的是对象,cookie里保存的是字符串
- session不能区分路径,同一个用户在访问同一个网站期间,所有的session在任何一个地方都可以读取到;而cookie如果设置了路径参数,那么同一个网站中不同路径下的cookie是互相访问不到的;
- session需要借助cookie才能正常生效,如果客户端禁止cookie的话,session将失效;
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
上一篇: 手把手带你学NLP领域最基础的任务模型
下一篇: 用AI搭建车辆监控与管理服务其实很简单!
精华推荐