
要不要一起爬山?百度大脑EasyDL邀你一起翻越企业AI落地的高山
日期: 2020-07-01 分类: 跨站数据 460次阅读
在企业AI模型的开发中,从数据准备到模型训练再到服务部署,每个环节都需要企业加以关注。数据的质量直接影响模型效果,企业需要高效率、低成本完成数据的采集、上传、清洗与标注并快捷接入模型训练。在传统医药物流行业的分拣业务中,药盒种类多、背景复杂、检测速度要求快,人工分拣和复核已难以满足需求。商务服务业、知识密集型产业则面临着海量数据的理解与处理难题,培养一名理解行业的员工需要耗时多年,但经验传授却难上加难,企业培养人才成本高。
EasyDL零门槛AI开发平台,面向企业开发者提供智能标注、模型训练、服务部署等全流程功能,针对AI模型开发过程中繁杂的工作,提供便捷高效的平台化解决方案。针对数据管理问题,EasyDL中的EasyData智能数据服务平台,提供覆盖采集、清洗、标注、加工等一站式数据处理功能,并与模型训练环节无缝对接,通过数据闭环功能支持高效的模型迭代。EasyDL面向不同人群提供了经典版、专业版、行业版三种产品形态,其中EasyDL专业版支持深度开发高精度业务模型,内置了丰富的预训练模型,能适用于多种场景,仅需少量数据即可达到优异的模型效果。
刚刚结束的EasyDL产业应用系列公开课从案例出发,为你带来行业洞察与模型开发实操演示,错过直播也不必担忧,本文精选三个经典案例,提取行业AI应用的核心知识点,助你翻越企业AI应用的高山!
核心解决问题:覆盖数据采集、清洗、扩充、智能标注的一站式数据服务
典型案例:智能云秤实现自动称重结算
面对疫情,减少人员聚集被反复强调。在社区果蔬店中,如何做到减少人员聚集,通过智能果蔬识别结算秤代替人工结算被中科立业所关注。但在数据准备阶段,主要遇到了两个问题:水果种类繁多,包装情况复杂,对数据量要求高;重复图片和模糊图片数量多,数据质量需要提升。这两个问题也不仅仅出现在这一个案例中,许多企业在采集训练数据时都会遇到采集上传困难、数据需预先处理耗费大量精力等问题。
为此,中科立业开始使用EasyData数据智能服务平台,通过将平台提供的SDK部署到智能秤的摄像头中,不仅可以自定义修改抽帧频率和运行时间,可根据果蔬店运营时段设定图片采集时间;还可以直接将摄像头采集到的一手图片数据,传输至EasyData平台,进行清洗、标注等后续操作。由于常见水果的出现频率高、部分采集图片模糊不清等原因,出现了大量重复图片与人眼都难以识别的模糊图片,中科立业使用EasyData数据清洗中的“去重复”与“去模糊”功能,去掉重复率高的图片与高模糊度的图片,优化训练数据,进一步提升数据集的质量。
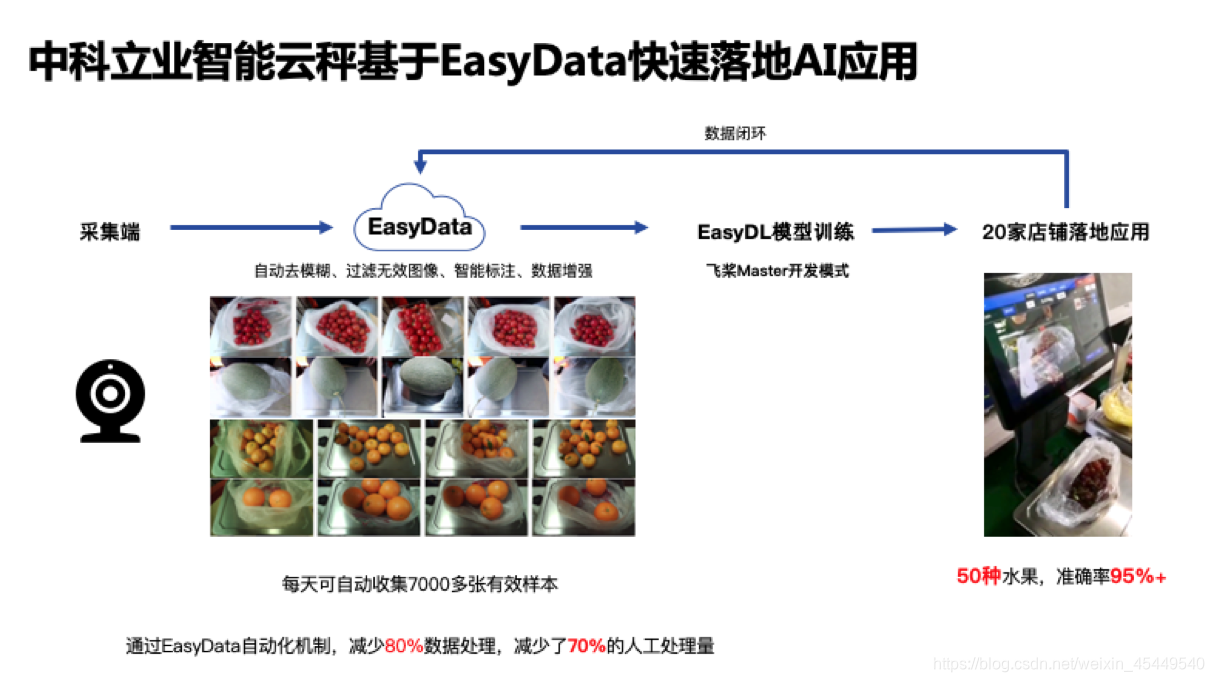
通过EasyData平台对数据进行采集、处理与标注,并依托EasyDL的图像分类模型进行训练,中科立业成功训练了一个果蔬识别模型,目前已经可以成功识别50种水果,识别准确率达到95%以上,已在20家店铺成功落地应用;同时,仍在持续优化模型效果、增加水果种类。
立即使用智能数据处理服务,可百度搜索“EasyData”或访问:https://ai.baidu.com/easydata/
核心解决问题:医药物流行业的分拣流程,机器人替代人工高效精准抓取
典型案例:药盒检测分拣模型的开发
近年来,随着互联网医药的快速发展、医药流通市场的逐步规范、零散药品内复核、整箱外复核的推行,医药物流行业显现出两个特点:拆零占比大、订单碎片化程度大。零散的药盒分拣与复核,单纯采取人工进行工作,每个工人负责的分拣区域较大,出库频率较低,这一工作方法在日益庞大的医药物流体系中难以长久维系。因此,越来越多企业希望把AI能力应用到产品与服务中,然而,基于开源框架的模型开发需要专业算法团队的支持,付出的成本使许多企业望而却步。
浙江工业大学信息工程学院的付老师,根据企业对高效率、高性能、低成本AI开发平台的需求,找到了EasyDL。
经过对分拣场景需要精准定位药盒这一需求的细致了解,付老师选择了EasyDL专业版的物体检测模型。为尽可能提高模型精度,在准备原始数据集时,与实际应用时选择了同样的设备与背景进行药盒采样,并尽量覆盖各种角度,以保证训练数据与实际业务数据尽量一致。EasyDL专业版的物体检测模型支持开发者根据自己对模型性能和精度的需求灵活进行网络选型,在药盒检测中,付老师推荐使用高精度的FasterRCNN、YoloV3或mobilenetSSD网络,也鼓励用户根据页面上的选型提示查看不同网络的特点。在启动训练后,付老师选择了支持数据闭环,持续不断优化模型效果。
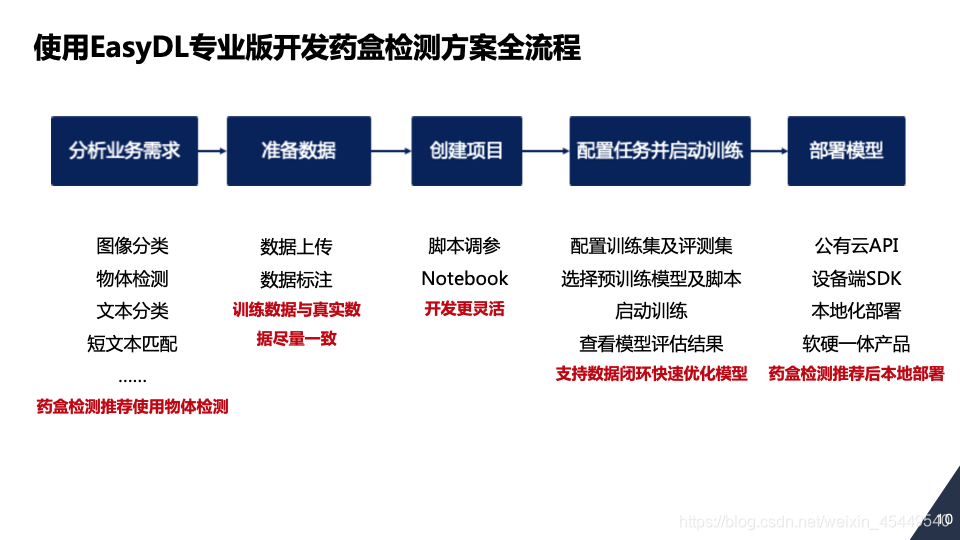 在具体部署时,企业需要根据应用场景进行选择。在药盒分拣场景中,对时延要求很高,因此推荐进行离线部署。付老师选择的EasyDL-EdgeBoard VMX加速卡软硬一体方案,将模型部署到VMX加速卡,直接集成到机械臂中。在实际落地过程中,该物体检测模型的3D定位精度精确到1-2毫米,每完成一次分拣任务的周期是7秒左右,并且相对人工覆盖区域更大,可24小时不间断工作,实现了分拣场景的智能化转型。
在具体部署时,企业需要根据应用场景进行选择。在药盒分拣场景中,对时延要求很高,因此推荐进行离线部署。付老师选择的EasyDL-EdgeBoard VMX加速卡软硬一体方案,将模型部署到VMX加速卡,直接集成到机械臂中。在实际落地过程中,该物体检测模型的3D定位精度精确到1-2毫米,每完成一次分拣任务的周期是7秒左右,并且相对人工覆盖区域更大,可24小时不间断工作,实现了分拣场景的智能化转型。
立刻尝试EasyDL专业版,可百度搜索“EasyDL专业版”或直接访问:https://ai.baidu.com/easydl/
核心解决问题:海量复杂文本的结构化与灵活部署
典型案例:猎头行业实现复杂文本分类
猎头行业作为知识密集型行业,看似门槛低,但在实际工作中要求从业人员对其所专注的行业拥有深入的认知和理解,只有掌握行业内不同公司的各类工作信息,才能为候选人提供全面的顾问咨询服务。因此,猎头行业中,从入门的小白到掌握行业信息的专家,往往需要多年的经验累积和知识沉淀。
然而,已经积累下的海量数据,是否能够通过结构化处理,将沉淀的历史数据和源源不断的新数据通过AI赋能变为规则化的标签,帮助从业人员进行快速解读被瀚才猎头的负责人谭笑然所关注。
在瀚才猎头的模型开发中,谭笑然分享了一个提升模型训练效率的关键点:数据清洗与关键信息的留存。在第一次进行模型训练时,十万条数据训练了近六天,效率很低。通过EasyDL后台工单的协助,重新进行了数据处理:首先对数据进行数字化统一,通过OCR等功能将不同格式的数据统一为文本格式;下一步进行数据的结构化,留下需要的模型数据,最后将冗余数据和模糊数据剔除。由此获得的高质量语料,在提升模型训练速度的同时,大大提高了模型的准确率。
瀚才猎头公司累积了10余年的近200万条候选人数据,通过EasyDL专业版的文本分类模型,将企业内部经营信息及候选人信息高效、安全、低成本地进行了结构化分类。由于EasyDL提供端云协同的多种灵活部署方式,用户可以根据自己的具体业务场景和训练的模型类型,选择适应的部署方式,包括公有云API、设备端SDK、离线服务器与软硬一体部署方案。在瀚才猎头的模型开发完成后,根据公司日常业务处理的需要,笑然将模型集成到公司工作管理平台,结合使用实现了海量数据的结构化处理,大大降低了学习成本与数据的处理成本。
快速开发高精度业务AI模型:百度搜索“EasyDL”或直接访问:https://ai.baidu.com/easydl/
以上三个典型案例,在数据处理、模型训练与服务部署各有侧重,是否也为你带来了AI落地产业应用的启发?在EasyDL产业应用系列公开课中,行业资深专家联手百度研发工程师,从行业深度解读到产品实际应用,帮助你快速理解业务、掌握技术,成长为一名懂行业的AI工程师,协助企业完成智能化转型的飞跃!
查看覆盖各行业经典案例:https://ai.baidu.com/customer?industry=0&technology=8&clickType=industry
课程重点回顾与录播视频,可百度搜索“EasyDL产业应用公开课”,或访问:
https://ai.baidu.com/support/news?action=detail&id=2075

对课程或产品使用有问题或建议,可微信搜索“BaiduEasyDL”添加小助手,或扫描下方二维码。

除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐