
【最佳实践】SequoiaDB集群扩容最佳实践
日期: 2020-12-14 分类: 跨站数据 773次阅读
前言
随着业务系统非结构化数据年增长量较大并且数据越来越多。在业务系统投产后,由于业务量的增加使得集群可使用存储容量逐渐变小,因此在业务系统接入集群前需考虑存储容量耗尽后整个集群的水平扩展。
SequoiaDB是分布式架构的多模数据库,因此可以通过集群的扩容实现集群性能的近线性增长。通过扩容后主要解决两个问题是数据存储的容量问题和整个集群的性能问题。因为数据量的不断增长及上线后的推广使用,所以需要进行扩容来提升集群性能及增加数据存储空间。
典型应用场景
1.旧数据量大,不希望移动数据;
业务系统库表数据量非常庞大,由于投产以来,业务量的持续增长,集群可用的存储容量消耗殆尽,没有多余的其他磁盘资源来满足移动旧数据的能力。期望能在不移动已经存在的旧数据的情况下,解决存储容量不够的问题,以满足后期业务增长的需求。
2.旧数据量不大,期望获得最好的性能,可以移动数据;
业务系统库表数据量不大,但包含日常业务操作,尤其是大量的前台操作,对查询的响应速度、并发量和吞吐量要求高。期望在数据量增长后,依然能够得到极致的读写性能。
3.完全不停服务,对应用透明;
业务系统存在数据存储容量或集群性能瓶颈,需要进行改善,但业务系统需要24小时对外提供服务,期望数据库的扩容动作对上层业务完全透明。
4.能够有停服务时间窗口,对应用透明;
和上述3场景类似,但能够有一定的时间窗口进行停止服务进行数据库变更,期望业务系统不需要改动,完成扩容的动作。
5.不改动数据库,希望更新应用;
应用代码比较容易变更,修改代码逻辑,完成集群的扩容。
优缺点对比
针对以上几种应用场景提供的几种不同解决方案优缺点对比:

每种解决方案在后面章节5将有具体介绍。
SequoiaDB支持扩容的特性
垂直分区
SequoiaDB的垂直分区也称作主子表,是将集合数据按照指定的分区键范围分别存储到不同的子表中,类似于传统关系型数据库中分区表的概念,主集合中不存放任何数据记录。
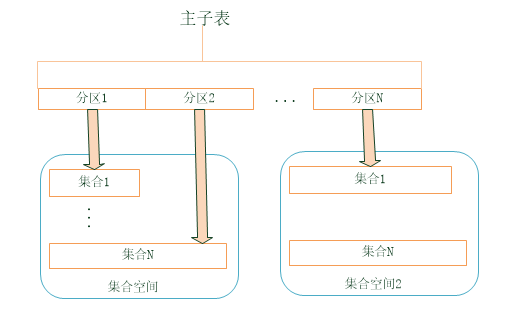
Split方法
集合的split方法,用作数据的切分,把存储在某些物理区块上的一个大数据量集合,按某一个或多个字段的值将之划分成若干个小的部分,将这些小的部分分散存放到更多的物理区块上。
数据迁移
SequoiaDB提供数据的导入(sdbimprt)和导出(sdbexprt)工具,能够将JSON格式或 CSV 格式的数据导入到 sdb 数据库,和将sdb 数据库集合中的数据导出到外部文件中。
应用案例
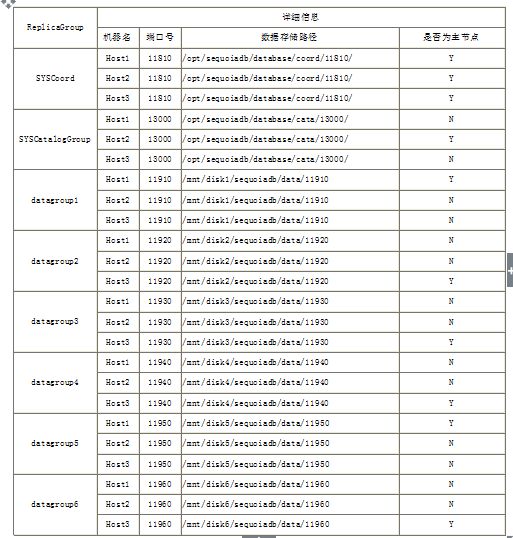
测试环境
V2.8.2的集群环境:
下面通过以上的几种特性的组合,完成几种不同场景下的扩容方法:
方法1:主子表+导出导入:
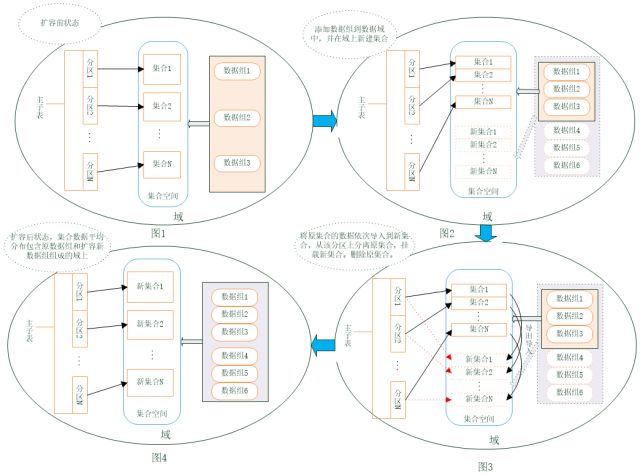
扩容前该主子表的每个子表(集合1-n)数据均匀存放在原数据域内数据组1-3上,如图1所示,目标是将每个子表(集合1-n)数据均匀分布到包含原数据组和新加入数据组的数据组1-6上,如图4所示,通过如下步骤进行扩容:
1)将新加入的数据复制组添加到域中;
2)在更新后的域中对主表的每个子表建立新的子表;
3)建立管道文件;
4)导出原子表数据到管道文件,同时导入管道文件中的数据到新子表中;
5)导出导入完成后,校验数据的正确性,从主表上分离原子表,挂载新子表;
6)删除原子表。
此方式适用于,原来的数据组数据未接近饱和,最接近饱和的数据组,能容纳最大数据量集合除以扩容后数据组个数的存储空间。由于主表名称不受扩容影响,分离原子表,挂载新子表速度很快,能不停机提供查询操作,不需要改动上层业务系统正常运转。但在迁移过程中,集合中数据不能变动。
方法2:主子表+split:
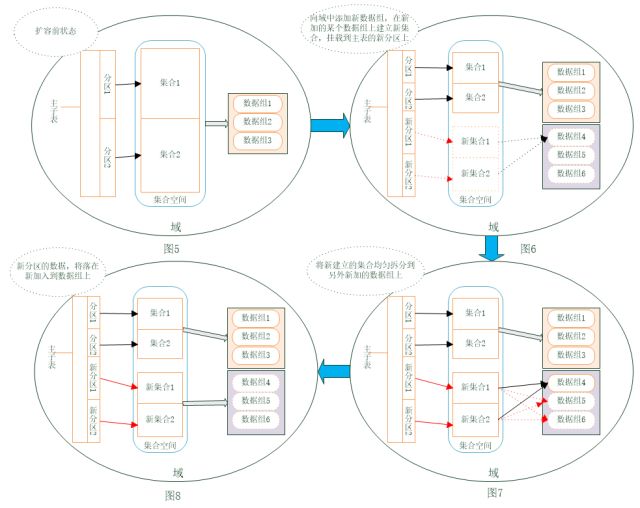
扩容前该主子表的每个子表(集合1、2)数据均匀存放在原数据域内数据组1-3上,如图1所示,目标是新增子表(新集合1、2),新数据均匀分布到新加入数据组的数据组上,如图4所示。
在建立子表时,设置autoSplit属性为false,使用Group属性,但使用Group指定集合建立的分组时,只能指定一个数据组,不能指定多个数据组。因此还需要在子表上,手动使用split方法,将数据范围切分到其他新增的数据组上。通过如下步骤进行扩容:
1)将新加入的数据复制组添加到域中;
2)在新加入的某个数据复制组上,建立新的子表;
3)使用split手动将新子表切分到其他新加入的数据组上;
4)挂载新的子表到主表上。
此方式适用于主子表,且主表和子表之间带有时间特性,业务系统过来的新增数据存入到新的子表中,在按年或月信息作主子表分区键时,在当前阶段的子表数据接近饱和时,通过新增下一阶段的子表,来存放下一阶段的数据。 对业务系统透明且无任何运转的影响。但由于Group只能指定一个分区组,手动切分比较麻烦。
方法3:主子表+数据域
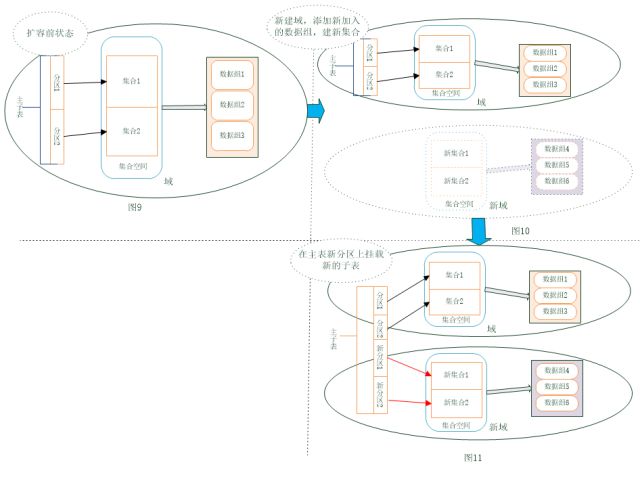
由于数据域的指定是在集合空间上,所以新的子表不能建在原集合空间上,需要新建集合空间,指定数据域为新的数据域。
1)在新加入的数据复制组上新建域;
2)在新的数据域上,建立新的集合空间;
3)在新的集合空间上,建立新的子表;
4)将新的子表attach到主表上。
和第三种方式差不多,适用场景一样,但少了手动切分的过程,替换为新增数据域和集合空间,利用域的autoSplit特性,自动完成切分过程。缺点是增加了域和集合空间,增加了复杂性。
方法4:普通分区表+split
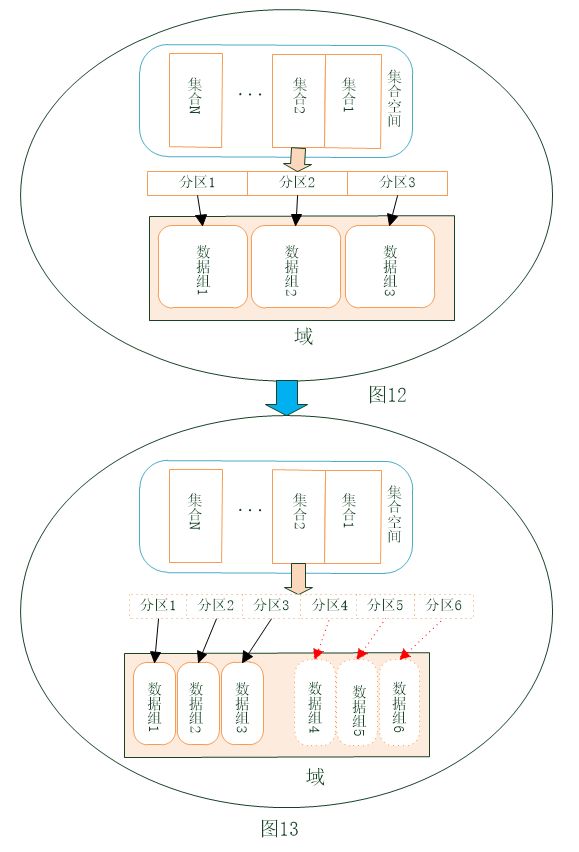
1)将新加入的数据复制组添加到域中;
2)使用split方法对域中的每个集合的数据,手动切分到新加入的数据组中。
最常规的一种方式,适用于非主子表结构的普通集合,能不停机提供查询操作。
注:在切分的过程中,从协调节点看,集合的数据量会存在波动;对该集合数据的增删改可能会出现问题,建议在没有修改操作的时候进行该切分操作。
方法5:普通分区表+导出导入
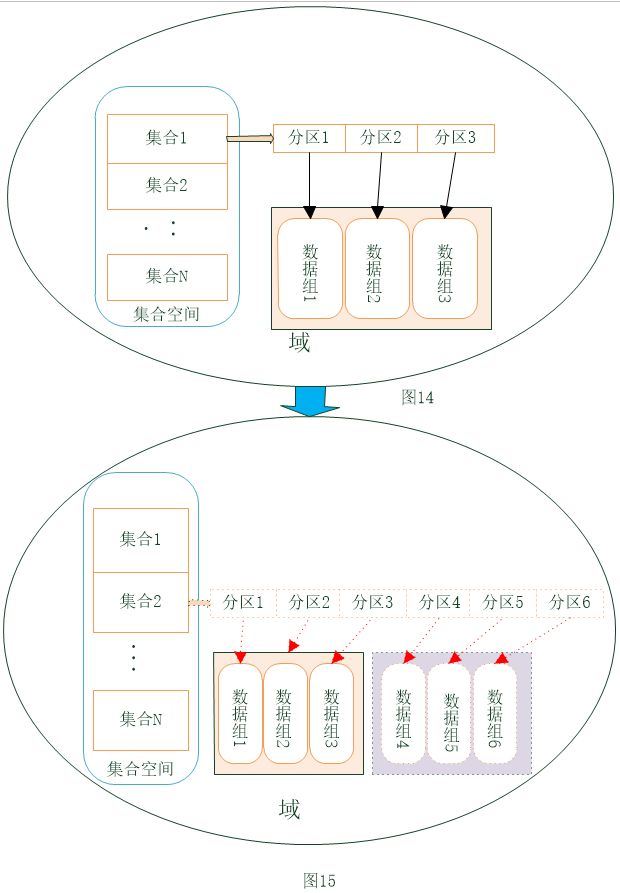
1)将新加入的数据复制组添加到域中;
2)导出域中所有的集合数据,以及集合空间定义、集合定义和索引定义;
3)删除域中原有的集合空间;
4)新建集合空间、集合以及索引。
5)导入之前导出的数据到新建立的集合中。
相当于是对整个域内的结构,进行重建,适用于集合空间、集合和数据组特别多,但域内数据量不多,或数据可以全部清空的场景。特别适用于初期建表测试时,发现表结构或容量不满足需求,需要重建的情况。
总结
在不同的适用场景下选择不同的扩容方式,如果扩容前,采用了主子表的存储方式,根据主表分区键的特征,选取不同的扩容方式,如果分区键带有时间特性(逻辑上某段时间入库的数据,只会落在某些子表上),譬如业务暂时存储近期内的数据,远期的数据存储在未来部署的机器上的场景,可以使用方式二和方式三,而当新增数据组特别多时,方式三工作量更小;如果分区键不带有时间特性,可以使用方式一。如果扩容前没采用主子表的存储方式,可以使用方式四。如果在业务数据存储规划前期(数据量较小的情况下),建表后,发现起初规划的存储空间不够用,需要增加数据组,可以使用方式五,快速重建表结构。
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐