
最佳实践2 | SequoiaDB同城双中心部署规划
日期: 2020-12-11 分类: 跨站数据 714次阅读
01 概述
近年来,随着网上银行、手机银行等各种互联网业务的迅猛发展,各行业数据中心的业务压力成倍增加,客户对于业务访问质量的要求也越来越高,保障业务系统7*24小时连续运营并提升客户体验成为信息部门的首要职责。
为适应互联网业务的快速增长,保障各业务安全稳定的不间断运行,提高市场竞争力,同时符合监管机构的要求,「同城双中心」、「两地三中心」正在成为银行的共同选择。基于分布式数据库原理架构,底层数据通过三副本保证其可靠性,因此大多数分布式数据库都会推荐使用「两地三中心」的部署模式。
然而并非每个客户都具备“三中心”的部署条件,因此「同城双中心」部署方案将是分布式数据库客户重点关注的方案。本文主要介绍SequoiaDB巨杉数据库在同城双中心架构下的最佳实践。
02 建设目标
同城双中心容灾的主要建设目标可以归纳为以下几点:
-
双中心双活流量分发
同城双中心具备流量分发功能,当主中心流量太大、负载太高时,可以把流量分发到容灾中心、业务系统也可根据业务的特性动态的把数据请求分发到不同的中心。
-
故障切换
当同城双中心内的网络、硬件、系统出现问题时,运维人员可第一时间获悉故障情况,中心内的各个节点实现自动主备切换,保证业务系统访问的连续性,实现数据库系统的RPO=0,RTO达到秒级。
-
环境一致性
同城双中心对应用来说应该是透明的,其对外服务时应提供统一接口,中心内部数据和服务能力需要完全一致,且随时处于可切换状态。
03 SequoiaDB容灾方案
SequoiaDB分布式同城双中心容灾解决方案是指两个数据中心均处于运行状态,是真正的双活容灾解决方案。主中心和灾备中心可以同时承担生产业务,确保数据库系统发生设备故障,甚至单数据中心故障时,业务无感知自动切换,实现RPO(Recovery Point Objective)=0,RTO(Recovery Time Objective)达到秒级(RTO与应用系统及部署方式有关)。
一般情况下,同城双中心采用“2+1”的三副本灾备架构,即主机房两个副本,备机房一副本。如果三副本中有1副本发生故障,根据SequoiaDB的高可用性架构,剩下的2副本可以继续工作;但是如果三副本中的2副本发生故障,剩下的1副本则无法正常工作。但是根据灾备系统的设计原则,剩下的1副本应该独立接管工作,这就和SequoiaDB自身的高可用性架构发生了冲突。
为了应对这种情况,SequoiaDB提供了针对集群环境的“分裂(split)”工具,其工作原理是:使某个副本能从原来的三副本集群中分裂出来,成为一个新的单副本集群,独立提供服务。除此之外,为了应对分裂之后的特殊处理,还提供了集群“合并(merge)”工具,其工作原理是:将分裂出去的单副本集群重新合并到原来的集群中,恢复成一个三副本的集群。
04 同城双中心灾备架构
该架构是基于SequoiaDB的三副本方案构建的同城灾备,其中两副本部署在本地机房中,一副本部署在灾备机房中,整个集群跨越本地与灾备两个机房,见图1。
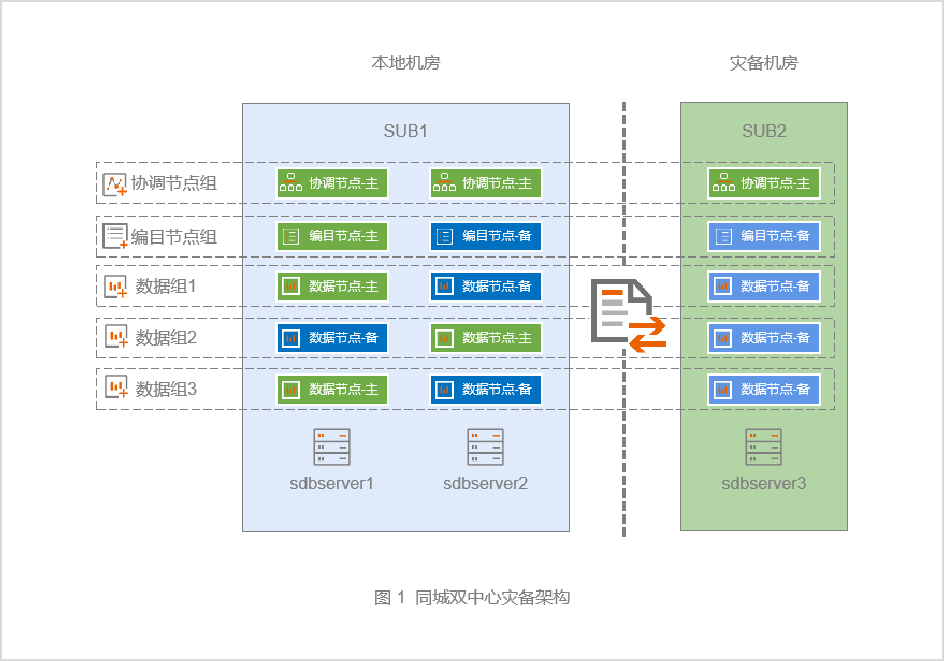
为了保证灾备机房与本地机房的数据保持实时一致,开启巨杉数据库中数据同步强一致性的功能。开启数据同步强一致性后,每次进行数据更新时,只有当存活的节点全部同步完成后,应用端才会收到更新成功的返回,这样就能在最大程度上保证了数据不丢失。
另外同城灾备网络的带宽有限,需要严格控制 SequoiaDB 集群对同城带宽的占用,阻止数据节点在异常终止后进行自动全量同步。用户应设置 sdbcm 节点参数 "AutoStart=FALSE” 和 “EnableWatch=FALSE",并设置每个数据节点参数“dataerrorop=2”。
根据 SequoiaDB 同城灾备集群部署情况,可以划分为两个子网(SUB),见表1。
表1 SequoiaDB 同城灾备集群部署子网情况
| 子网 | 主机 |
| SUB1 | sdbserver1,sdbserver2 |
| SUB2 | sdbserver3 |
05 灾难应对方案
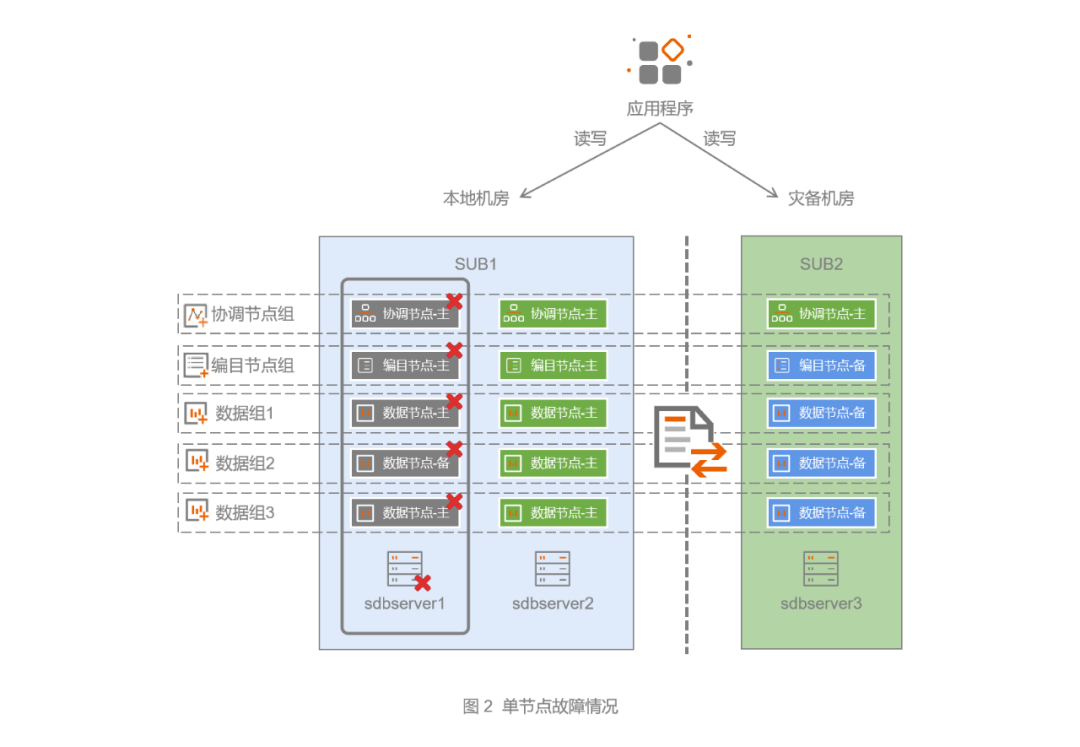
5.1 单节点故障
由于采用了三副本高可用架构,个别节点故障情况下(见图2),数据组依然可以正常工作。针对个别节点的故障场景,无需采取特别的应对措施,只需要及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
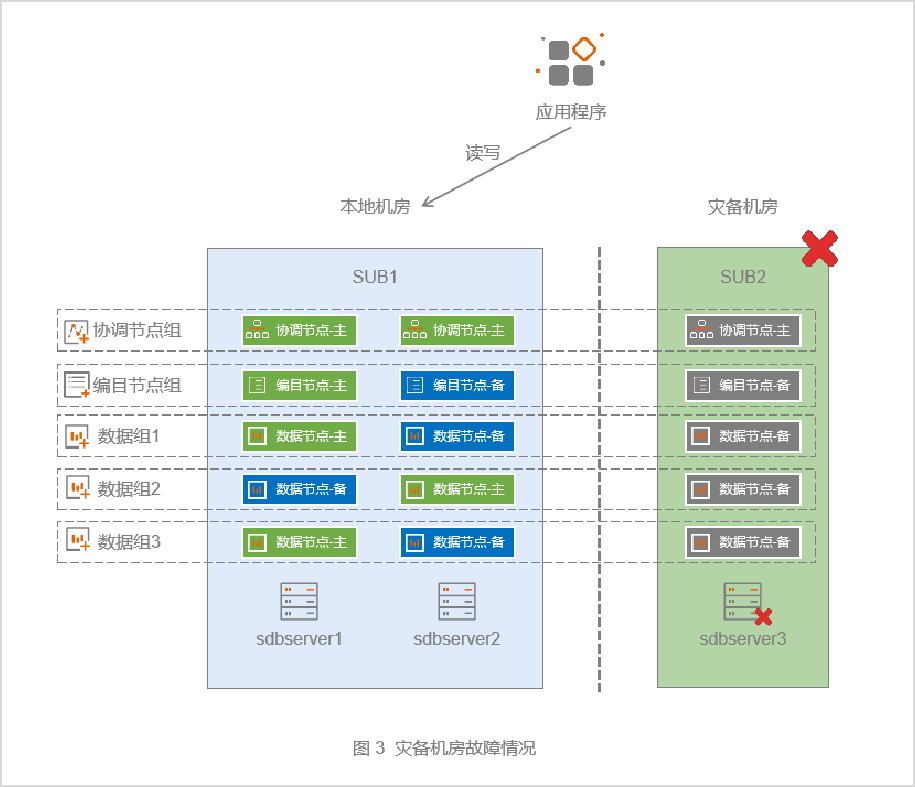
5.2 灾备中心整体故障
当灾备中心(SUB2)发生故障时(见图3),由于每个数据组都有两个副本部署在主中心(SUB1)中,每个数据组存活节点的数量还大于每个数据组的总节点数的1/2,所以每个数据组仍然能够为应用层提供读写服务。针对灾备中心整体故障的场景,无需采取特别的应对措施,只需要及时修复故障节点,并通过自动数据同步或者人工数据同步的方式去恢复故障节点数据即可。
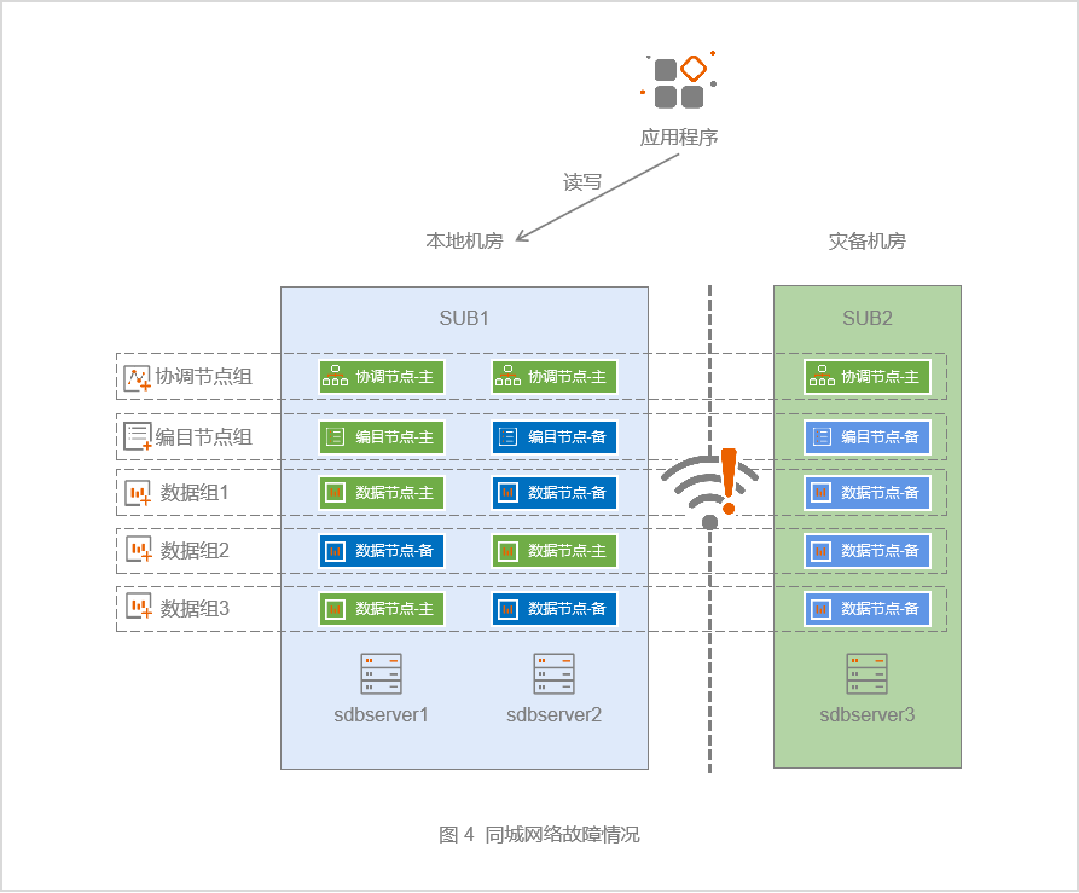
5.3 同城网络故障
当同城网络出现故障,导致主中心与灾备中心无法进行通信时(见图4),由于采用了三副本的架构,应用程序可以通过访问本地两副本集群。针对同城网络的故障场景,无需采取特别的应对措施,只需要及时修复网络故障,修复后通过自动数据同步或者人工数据同步的方式去恢复灾备节点的数据即可。
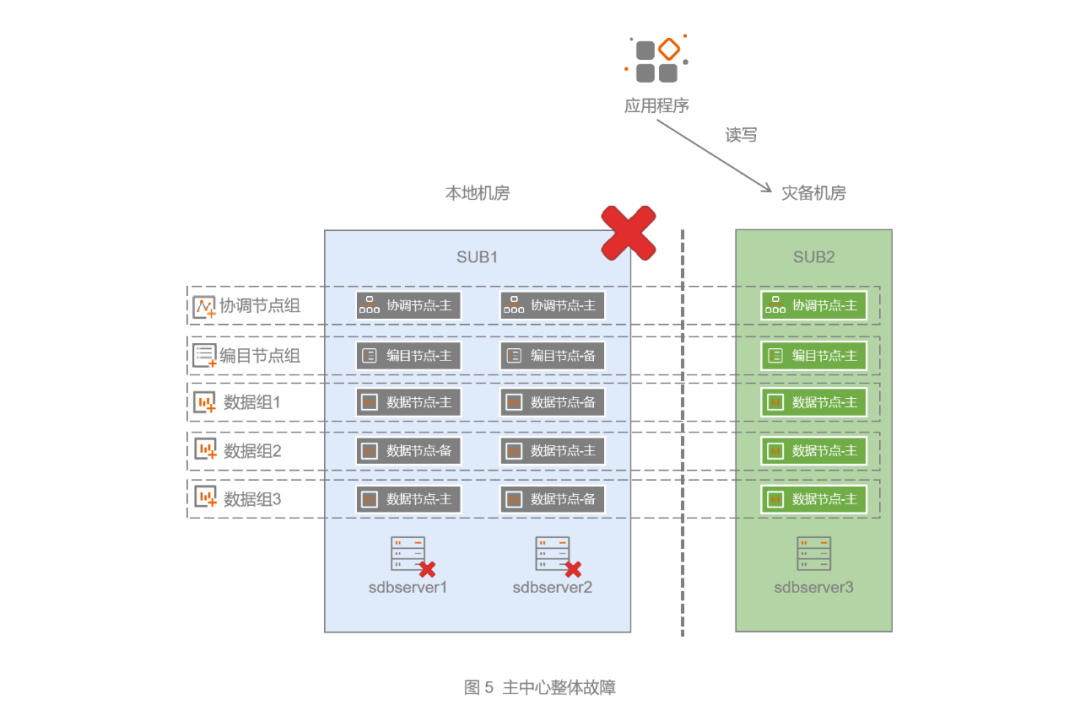
5.4 主中心整体故障
当主中心(SUB1)整体发生故障,整个集群环境将会失去三分二的节点(见图5),如果从每个数据组来看,相当于每个数据组有两个数据节点出现了故障,存活的节点只剩余一个。这种情况下就需要用到“分裂(split)”和“合并(merge)”工具做一些特殊处理,把灾备中心的集群分裂成单副本集群,这时灾备中心节点可提供读写服务。
06 总结
通过以上实例介绍了巨杉数据库的同城双中心灾备架构以及应对方案,在同城双中心架构下通过主备节点自动切换,保障了业务系统访问的连续性。接下来,我们将通过实践进一步地告诉大家如何利用巨杉数据库的灾难恢复工具进行容灾处理,敬请留意公众号下一篇文章《最佳实践3|SequoiaDB同城双中心灾难恢复工具》。
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐