
机器学习基础概念
日期: 2020-12-12 分类: 跨站数据测试 564次阅读
机器学习(Machine Learning)
百度搜索 : 机器学习涉及概率论、统计学、逼近论、凸分析、算法复杂度理论多门学科。研究计算机怎样模拟、实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能 . 是人工智能的核心,使计算机具有智能的根本途径,应用遍及人工智能的各个领域,主要使用归纳、综合 .
什么是建模
建模是指利用模型学习已知结果的数据集中的变量特征,通过一系列方法提高模型的学习能力,最终对一些结果未知的数据集输出相应的结果.
可以表达成 y=f(x) 其中x代表样本的特征, y是输出的结果
机器学习方法
监督学习Supervised learning
监督学习两大问题: 分类classification、 回归regression
监督常见模型:
- 最近邻( KNN ): 适用于小型数据集 , 是很好的基准模型 , 容易解释 .
- 线性模型( Linear Regression ): 非常可靠的首选算法 , 适用于非常大的数据集 , 也适用于高维数据.
- 朴素贝叶斯( Naive Bayes ): 只适用于分类问题 , 比线性模型速度还快 , 适用于非常大的数据集和高维数据 , 精度通常要低于线性模型.
- 决策树( Decision Tree ): 速度很快 , 不需要数据缩放 , 可以可视化 , 很容易解释 .
- 随机森林( Random Forest ): 几乎比单棵决策树的表现要好 , 鲁棒性很好 , 非常强大 , 不需要数据缩放 , 不适用于高维稀疏数据.
- 梯度提升决策树: 精度通常比随机森林略高. 与随机森林相比 , 训练速度更慢 , 但预测速度更快 , 需要的内存也更少 . 比随机森林需要更多的参数调节 .
- 支持向量机( SVM ): 对于特征含义相似的中等大小的数据集很强大 , 需要数据缩放 , 对参数敏感 .
- 神经网络 : 可以构建非常复杂的模型 , 特别是对于大型数据集而言 , 对数据缩放敏感 , 对参数选取敏感 , 大型网络需要很长的训练时间 .
每个模型都有自己的优缺点, 复杂度也不一样, 设置正确的参数对于性能至关重要.输入数据的方式也很敏感,尤其是特征的缩放.
无监督学习unsupervised learning
无监督学习: 数据集只给特征,不给标签,不需要人为标注给出语料答案.
无监督学习包括没有已知输出、没有知道学习算法的各类机器学习, 无监督学习中只有输入数据, 需要从这些数据中自己学习挖掘信息.
两种类型的无监督学习:数据集变换与聚类
经典的算法:k-聚类、主成分分析
半监督学习semi supervised learning
半监督学习介于监督学习和无监督学习两者之间,已知数据和部分数据对应标签,有一部分数据无标签.
模型学习已知标签和未知标签的数据 , 将输入数据映射到标签的过程 .
强化学习reinforcement learning
强化学习是一种学习模型 , 它不会直接给你解决方案 , 需要通过试错的方式去寻找 , AlphaGo就是用的强化学习 .
数据集分类
训练集、验证集、测试集
训练集: 结果已知,用于模型训练拟合的数据样本, 占总体的70%~80%
验证集:结果已知,不参与模型训练的拟合过程, 用于验证已经训练过的模型效果.同时对模型中的超参数进行选择
测试集:结果未知,测试机器训练结果的准确性,或是利用模型输出结果的数据集
测试机与训练集最好独立分割,不可重复使用.
模型在真实数据上预测的结果误差越小越好。模型在真实环境中的误差叫做泛化误差,最终的目的是希望训练好的模型泛化误差越低越好。
评价指标TP/FP/FN/TN
- True positive(TP): 真正例,将正例正确预测为正例数;
- False positive(FP): 假正例,将负例错误预测为正例数;
- False negative(FN):假负例,将正例错误预测为负例数;
- True negative(TN): 真负例,将负例正确预测为负例数。
P/N代表预测值,如预测值与真实值一样,则是真x例,反之是假x例。
文字模型、图片模型、策略分析
文字模型:用于机器检测语料中的命中目标: 大多是文字、语句、关键词,多应用于对文字语料爬取信息等进行风险识别、黑词识别等
图片模型:用于机器检测图片中的命中目标: 也可对艺术字,变体字进行识别,或识别对图片中的敏感标志、人物、政治宗教、风险物品进行捕捉、定位、识别
策略分析:在明确策略应用场景, 通过验证策略命中数据是否正确,分析策略误杀数据的特征.给出优化方案
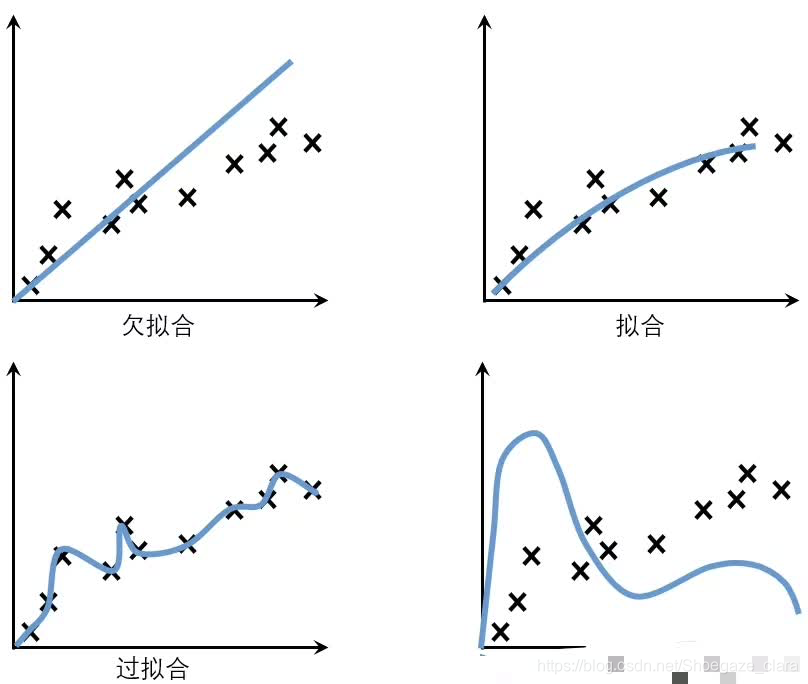
模型的泛化与拟合
泛化: 指机器学习算法对新鲜样本的适应能力。 学习目的是学到隐含在数据背后的规律,对具有同一规律的测试集以外的数据,经过训练也能给出合适的输出,该能力称为泛化能力。
即 : 经训练样本训练的模型需要对新样本做出合适的预测,这是泛化能力的体现
把模型训练的过程比作人类学习过程
欠拟合:泛化能力弱,新题老题不会做
过拟合:泛化能力弱,遇到新题就懵逼
不收敛:新题旧题全靠猜
拟 合:学霸,新题旧题大概率都可做出来
模型的准确率、召回率、正确率
(二分类问题中的重要指标,其中语料同样本)
模型准确率:机器分类正确的正例样本 占 分类为正例样本总数中的比例
分类为正例样本包括 : 真正例TP + 假正例FP(将负例判断成正例)
precision = TP/(TP+FP)
模型召回率:机器分类正确的正例样本 占 真正正例样本总数的比例
真正正例样本总数包括: 真正例TP+ 假负例(将正类错误判断为负类数)
Recall = TP/(TP+FN)
模型正确率:指机器分类判断正确的数量
accuracy = TP+TN / (TP+FN+FP+TN)
模型衰减与模型迭代
模型衰减:如随着时间的推移和线上素材的复杂性和多样性,机器训练模型的准确性会慢慢衰减. 其他应用场景暂不涉及
模型迭代:为了避免模型衰减带来应用效果结果不准确,通过定期的语料样本迭代,优化机器模型,保证模型应用效果
以上持续更新中
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
标签:机器学习 机器学习
精华推荐