
百度大脑EasyDL端计算能力:支持十余种芯片,多倍提速,只要一键部署!
日期: 2020-05-28 分类: 跨站数据 489次阅读
从科研、金融、零售到工业、农业等越来越多的行业与业务场景正在应用人工智能提升效率,降低成本。人工智能在产业升级、改善人类生活等方面发挥着越来越重要的作用。当开发者部署AI模型时,会面临一个使用场景的问题:不同的使用场景和业务问题中对模型的部署方式要求不同。
AI模型有着多样化的部署方式,常见的模型部署形态分为两种:服务器部署(AI云计算)和嵌入式部署(AI边缘计算)。服务器部署指的是将模型部署在CPU/GPU上,形成可调用的API接口,根据需要可选择云服务器部署和本地服务器部署;嵌入式部署指的是部署到边缘侧或端侧的嵌入式设备中,进行单机离线运行。下表对比了这两种部署方式的特性。当用户的模型应用场景没有网络覆盖,或是业务数据较为机密,或是对预测延时要求较高时,往往会选择嵌入式部署方式。
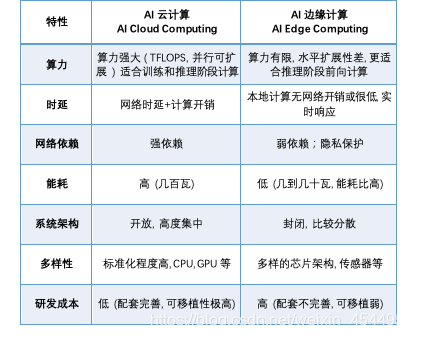
嵌入式部署方式具有实时响应、网络开销低、隐私保护、能耗比高等优势;但同时,由于边缘设备种类繁多,适配部署难度较高。
在一项百度和波士顿咨询公司的联合调研中,我们发现在有定制业务模型需求的客户中,超过35%的场景有离线边缘计算的需求。而如上文所述,端计算由于设备的多样性,研发和部署成本相比云部署更高,且往往实际业务场景对在端上运行的模型的时延和稳定性也会有极高的要求。因此,如何将定制好的模型部署到各类端设备上是一个技术难题。
为了满足开发者对部署形式多样化的需求,百度大脑一站式零门槛AI开发平台EasyDL支持多种部署方式,包括公有云部署、本地服务器部署、设备端SDK和软硬一体解决方案。EasyDL是基于飞桨推出的面向企业打造的一站式零门槛AI开发平台,提供智能标注、模型训练、服务部署等全流程功能等全流程功能,内置丰富的预训练模型,面向不同人群与需求提供经典版、专业版、零售版三个版本。
EasyDL支持的多种部署方式,适用于各类业务场景与运行环境,便于开发者根据需求灵活选择,其支持的设备也非常丰富,从最常见的x86、ARM、Nvidia-GPU,到NPU、FPGA,支持超过10类硬件。由于百度飞桨深度学习平台相关功能的支持,EasyDL具备强大的端计算部署能力,在生成端计算模型时,会经过一些列的优化、加速、压缩功能。
对于这一系列能力的讲解,可以从网络结构层面和芯片能力两方面入手。
在网络结构层面,会进行op融合(如conv-add-relu,conv-bn等)、fp16/int8量化、模型裁剪等优化。
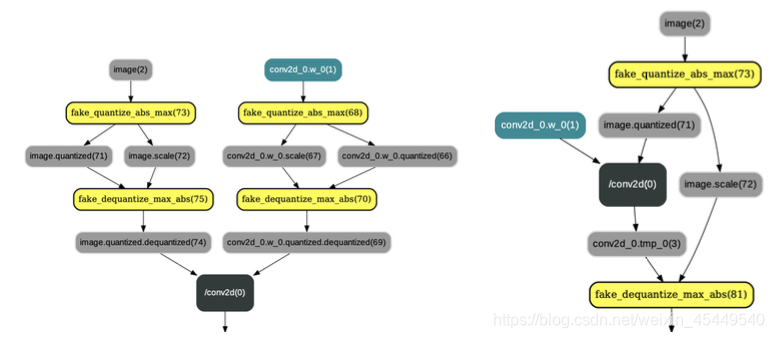
以近期上线的ARM定点量化为例,其优点包括低内存带宽、低功耗、低计算资源占用。在一些网络中,可以带来4倍的模型压缩、4倍的内存带宽提升,以及更高效的cache利用。在很多场景中,定点量化不会对网络精度造成额外损失。量化主要分为两大类:Post Training Quantization和Quantization Aware Training,前者是使用KL散度等方法确定量化参数且不需要重新训练的定点量化方法,后者是对训练好的模型做再训练,建模来确定量化参数。在量化训练过程中,前向传播的工作流可以表示为如下方式:

在训练量化的过程中,会在原有网络算子前后插入连续的量化op和反量化op,并改变相应的反向算子的输入,评估阶段,将量化算子参数变为量化后的值,最终通过PaddleLite的工具改变模型文件中的参数数据类型为int8的naïve buffer形式。
在后续的版本升级中,EasyDL会继续上线模型裁剪优化。基于敏感度选择最优的裁剪率组合来进行部分的卷积和裁剪,可以达到一倍以上模型体积的减少和低于1%的精度损失的优化效果。结合定点量化以及后续的蒸馏策略,模型的体积和推理速度会得到更进一步的全面优化。
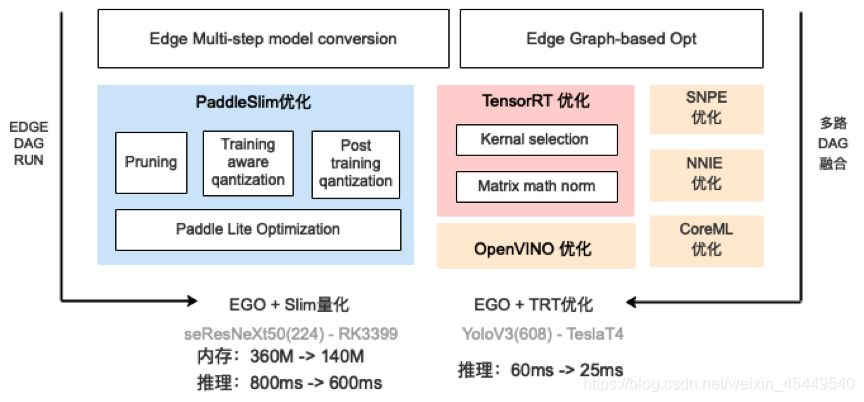
在芯片层面,EasyDL会根据具体的硬件类型进行特属优化。比如在ARM64上如果芯片支持NEON,会充分利用其16个128位寄存器进行浮点数计算的优化;在英伟达GPU设备上,EasyDL会利用TensorRT库进行子图的计算和加速;在苹果手机上,会利用CoreML引擎进行推理加速;在华为手机上,如果支持DDK,会调用华为HiAI引擎进行推理。此外,EasyDL还支持英特尔的 MKL OpenVino, 高通的SNPE等推理引擎。在一些平台上,能够根据具体的深度学习网络、芯片类型进行合理的自动选择,在保证精度的同时最大化利用芯片能力,极大地提升推理速度。经过网络、硬件等各层面的优化之后,模型在体积、内存占用、推理速度上都会有更优的表现,部分模型的推理速度可以提升数倍以上。
近期EasyDL新上线了华为Atlas 200、Atlas300加速卡的支持,能够支持最新DaVinci架构的昇腾310AI处理器,同时兼顾开发板及服务器的场景。结合EasyDL现有的优化技术,在EasyDL的高性能模型上,可以达到6ms的性能。开启多Batch优化后,单张300加速卡可以一秒处理高达1000张图片。
在EasyDL平台上,模型加速优化的全过程都会在系统中自动完成,用户只需根据自己的场景需要,选择具体的硬件,即可自动生成适配对应硬件的端计算部署包。现在,在发布模型的时候,用户只需要勾选“同时获取加速版”,EasyDL后台便会自动为用户生成具备量化、压缩等优化能力的加速版模型和SDK,用户可以直接下载使用,使用的流程也基本一致。总的来看,EasyDL的嵌入式模型部署整体使用流程非常快速便捷,用户无需关注复杂的深度学习边缘计算算法、具体硬件适配等底层逻辑,只需关注实际的业务需求,通过SDK输入图片即可获得模型输出的识别结果。
目前,已有多家企业根据具体业务场景,通过EasyDL平台仅用少量业务数据训练高精度AI模型,并根据使用场景和运行环境选择适配的部署方式。使用门槛低、方便快捷的加速版SDK具备的量化压缩等能力,正在越来越多的业务场景中发挥作用,快速解决业务需求。
立即尝试EasyDL:https://ai.baidu.com/easydl/
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
标签:百度大脑 部署 端计算
精华推荐