
【巨杉案例】银行高并发实时账单查询
日期: 2020-12-04 分类: 跨站数据 600次阅读
前言
银行的核心系统上的交易流水仅会保存近期的数据,此前,银行在柜面进行账单查询时也仅能查询近期的数据。其他的历史流水,银行会采用离线存储的方式将数据归档至磁带库、光盘库或者将数据至别的系统。这样的数据架构归划模式使得柜面系统上很难实现更多的历史账单柜面查询。
1.面临的挑战
如果需要支持客户的历史账单柜面查询及打印,那么则要把全行核心系统所有的历史流水数据进行统一存储。历史账单柜面查询时有一个最重要的前提,那就是不能够对现有的柜面核心交易系统产生影响。此前提的存在就使得历史账单数据和核心交易系统数据不能够共用一套系统。
历史账单柜面查询除了要满足不影响柜面核心交易,而且需要能满足高并发,高实时的查询。因为银行一般都有成百上千个营业网点,所以历史账单柜面查询的并发支持要好。柜面查询一般有几十秒的超时限制,如果查询超过这个时长,柜面就会直接把连接断掉,所以对查询的实效性要求比较高。历史账单的查询是从整个核心交易的所以历史交易流水中进行数据查询的,而且账单查询的时间跨度往往是半年,甚至是一年。如此大范围的查询带来的是大结果集的返回,这更是为查询性能带来了影响。
针对以上的查询需求特点,解决方案需要解决以下几点需求:
海量历史数据低成本存储及管理
历史账单查询是从海量历史数据中进行数据的筛选操作,所以需要先将海量数据进行统一存储和管理。历史账单查询不需要有如核心交易系统那样高级别的数据处理需求,所以也不可能像建设核心交易系统那样进行高配置的硬件资源(如大机)和高成本的投入来构架历史账单柜面账单查询系统。
新旧系统数据统一
银行的各系统在整个历史中进行了多次的升级改造,这就导致了新旧系统之间数据存储设计上存在着极大的差异。为了能提供高效、便捷、无缝的历史账单数据查询,新旧系统之间数据的整合也是必不可少。
提供高并发高时效的数据查询
历史账单柜面数据查询要能够满足上千网点的并发访问,且要达到秒级返回。历史账单查询时需要能从海量历史数据中查询半年甚至一年的数据,这就对数据的查询提出了很高的性能要求。
2.解决方案
账单柜面查询架构如图所示,此架构由下到上可分为历史账单数据采集、账单数据存储管理以及柜面查询网关应用。历史账单数据存储管理是整个历史账单柜面查询的核心,主要基于SequoiaDB分布式数据库完成。基于此架构,历史账单柜面查询实现上千银行网点的并发实时访问。
银行账单查询平台架构图:
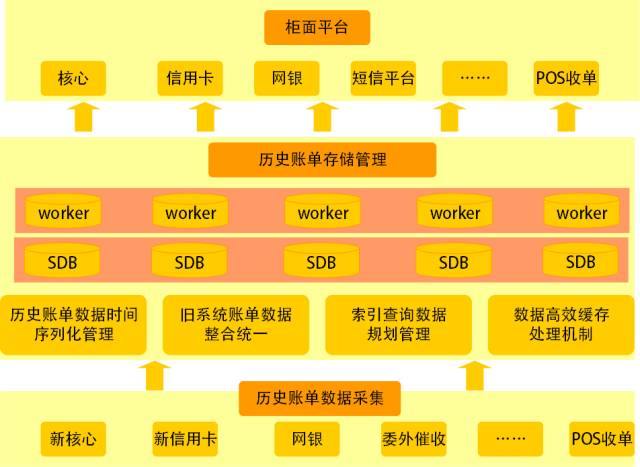
2.1历史账单数据采集
历史账单数据采集的主要作用是为历史账单数据存储提供历史账单柜面查询所需的各业务系统数据。历史账单数据采集程序通过将新核心、新信用卡及网银等业务系统准备的历史数据采集回来,将采集的数据按统一格式进行数据存储。
2.2历史账单数据存储管理
历史账单数据存储管理主要工作是完成历史账单数据的统一规划、加工和存储管。历史账单数据存储管理根据采集数据,再结合历史账单柜面数据查询需求,用SequoiaDB+Spark构建的分布数据处理平台完成数据的规划、入库以及加工处理。
1)历史账单数据时间序列化管理
历史账单数据作为用户的历史交易流水数据,存在很强的时间特性。针对此时间特性的数据,采用时间序列化的方式可以很好的展示和管理银行自发生交易以来每个时间节点的历史账单数据。SequoiaDB数据库表的时间序管理机制能很好的支持和完成历史账单数据的时间序列化存储和管理,同时也能为历史账单数据时间范围提供高效的查询。如将核心历史账单数据根据硬件资源、历史账单交易聚集情况以及柜面查询使用情况按年或者月进行合理的时间序列化存储和管理。柜面操作员在进行历史账单数据查询时可以根据条件中的时间范围快速精准的定位到账单数据,高效快速的查出数据给客户。
2)旧系统账单数据整合统一
由于新旧系统的更替及旧系统设计的历史性,同一套系统的新旧系统数据表结构存在极大的差异,且旧系统数据在存储大量历史数据的情况下也不利用数据的查询。为了实现新旧系统数据统一和高效快速的查询,历史账单数据在存储时会需要根据历史账单数据查询需求对旧数据进行整合加工处理。数据加工通过Spark分析框架将存储于SequoiaDB中的数据根据新旧系统结构的统一规划完成数据加工处理,如将多张历史账单数据流水表打平成为一张数据流水表,然后提供柜面快速的查询。
3)索引查询树规划管理
历史账单数据除了存在时间特点外,还存在数据量非常大的特点。从海量的历史流水数据中使用表扫描的方式进行查询肯定是不现实的,所以为数据规划索引就显得特别的重要,其直接决定了历史账单柜面查询的性能。SequoiaDB除了支持单键索引,同时也支持多键联合索引。在进行索引查询树的规划时,需要根据机器内存、查询的条件、数据分布情况和查询结果集等因素进行索引的合理规划,从而提高查询的性能。如果索引查询树规划不够合理,不仅无法提高查询性能,反而会降低查询性能,甚至会导致大量随机I/O,造成I/O拥堵,从而影响别的查询请求。
4)数据高效缓存处理机制
众所周知,历史账单数据是持久化存储至磁盘上的,历史流水的写入与查询实质是对磁盘进行写读操作。数据在进行读写过程中,内存与磁盘进行着频繁的交互。因为磁盘是低效存储,所以在数据读写过程中,数据读写的瓶颈往往是在磁盘的I/O上。为了优化处理此问题,SequoiaDB结合Linux的MMAP数据缓存机制对数据进行了数据的高效缓存处理,如索引数据等数据。除了对索引数据进行缓存外,常用的历史账单数据也会进行缓存处理,以提供给柜面快速高效的查询。
2.3 柜面查询网关应用
柜面查询网关应用主要是对各类业务系统进行对接及管理操作,如核心、信用卡以及网银等数据。柜面查询网关会记录柜面查询的具体情况,如柜面查询请求数、后台数据处理数据等。同时,它还对整个柜面网关查询进行超时设置,对于查询超出规定时长的请求,会直接进行中断处理。
3.项目成果
3.1海量数据低成本存储
SequoiaDB数据库采用分布式架构,只需要普通X86 PC Server即可完成海量数据的高效存储。由于业务数据存在离线化、海量化、分散性及查询低频性等特点,所以廉价的在线存储架构使离线数据实现在线化成为可能。
3.2历史账单数据统一存储管理
历史账单柜面查询涉及多个业务系统,所以对多个业务系统数据的规划存储和统一管理则显得非常重要。SequoiaDB的Domain功能及元数据信息的有效管理很好的实现了多系统数据的统一存储及管理。
3.3柜面账单实时查询
历史账单柜面查询的数据存储在SequoiaDB分布式数据库之后,历史数据可以进行实时查询。SequoiaDB分布式存储+多键联合索引机制完成一个历史账单柜面查询请求任务秒级返回的结果。

起飞

相关阅读:

除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐